DeepSeek R1 架构和训练过程
本文翻译整理自:Drawing DeepSeek R1 Architecture and Training Process from Scratch
1、概览
DeepSeek-R1 并非从零开始训练,而是以 DeepSeek-V3 为基础开始训练,并希望优化其推理能力。为了实现这一目标,采用了强化学习,即当 LLM 在推理方面表现出色时就给予奖励,否则就进行惩罚。
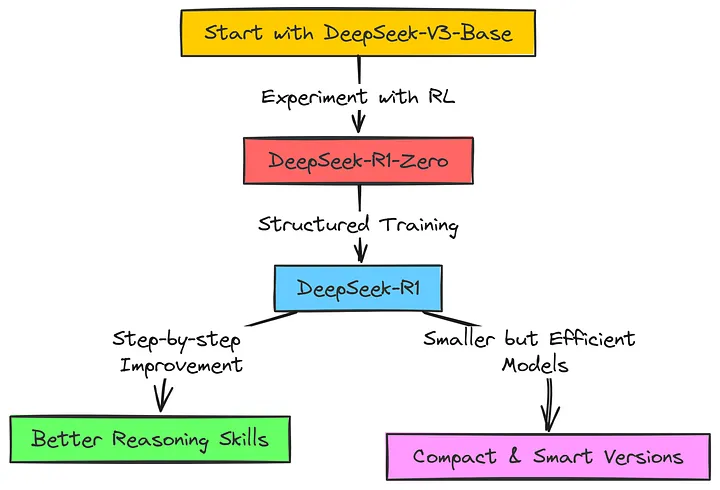
但这并非只是一次简单的训练过程。首先尝试仅使用纯强化学习,看看推理能力是否会自行显现,即 DeepSeek-R1-Zero。然后对于真正的 DeepSeek-R1 通过不同的阶段使其训练更有条理。Deepseek 团队先给模型提供一些初始数据让其启动,然后进行强化学习,接着提供更多数据,再进行更多的强化学习 ……
整个过程的核心是让这些语言模型在思考问题和给出智能答案方面表现得更出色,而不仅仅是随意输出文字。
2、DeepSeek V3(MOE)是如何思考的?
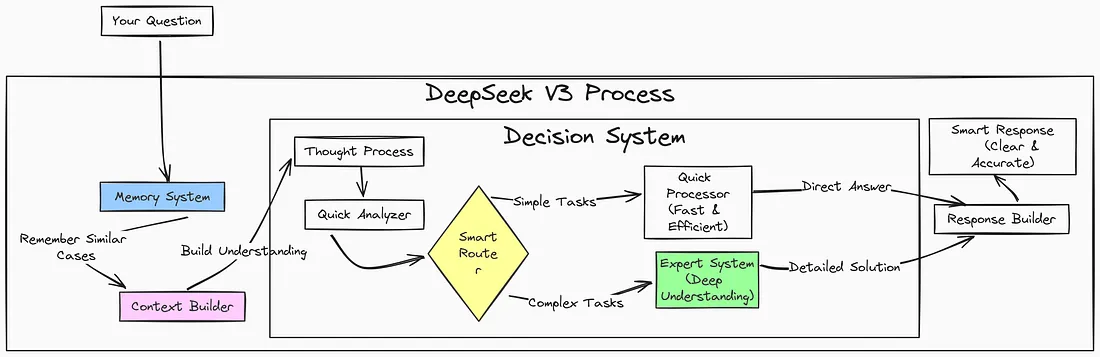
DeepSeek V3 的运行主要有两条路径。当你输入一个问题时,它首先会经过一个记忆系统,该系统通过查找相关信息快速构建上下文。可以把这想象成快速回想起你之前遇到过的类似情况。
它的主要优势在于其决策系统。在理解你的输入内容后,它会使用一个智能路由,在两条路径中做出选择:一条是用于处理简单任务(比如简单的问题或常见的请求)的快速处理器路径,另一条是用于处理复杂问题(比如分析或专业知识)的专家系统路径。
正是这个智能路由让 DeepSeek V3 成为了一个混合专家模型(MOE),因为它能动态地将每个请求导向最合适的专家组件,以便进行高效处理。
简单的问题通过快速路径能得到快速、直接的答案,而复杂的查询则会通过专家系统得到详细的处理。最后,这些回复会被整合为清晰、准确的输出内容。
3、在强化学习设置中作为策略模型(执行者)的 DeepSeek V3
DeepSeek R1 初始版本(R1 Zero)是使用强化学习创建的,在这个过程中 DeepSeek V3 充当一个强化学习智能体(采取行动的执行者)。
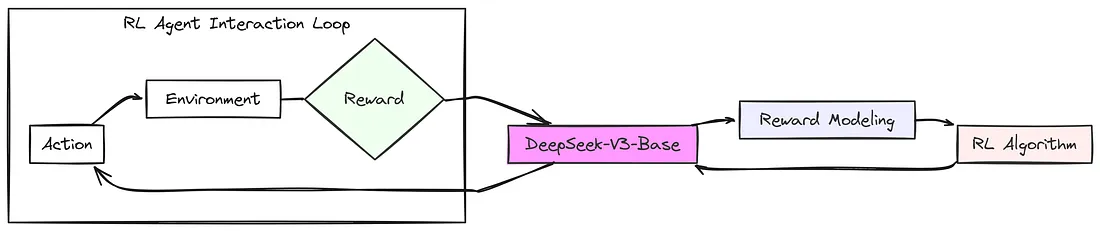
强化学习智能体(DeepSeek V3)首先采取一个行动,这意味着它针对被输入到其环境中的给定问题生成一个答案和一些推理过程。在这种情况下,环境仅仅就是推理任务本身。
采取行动之后,环境会给出一个奖励。这个奖励就像是一种反馈,反映 DeepSeek V3 基础模型行动表现如何。正奖励意味着它做对了某些事情,也许是答案正确或者推理得很好。然后这个反馈信号会返回到 DeepSeek-V3-Base,帮助它学习并调整未来采取行动的方式,以便获得更好的奖励。
在接下来的部分中,我们将讨论这种带有奖励模型的强化学习设置以及所使用的强化学习算法,并尝试使用我们的文本输入来解决相关问题。
4、GRPO 算法是如何工作的?
训练 LLMs 在计算方面成本极高,而强化学习则增加了更多的复杂性。
传统的强化学习会使用一种被称为 “critic” 的组件来辅助主要的决策部分(“actor”,即 DeepSeek V3)。这个 critic 通常和 actor 本身一样庞大且复杂,这基本上使计算成本增加了一倍。
然而,GRPO 的工作方式有所不同,因为它直接从一组行动所获得的结果中找出一个基线,即一种衡量良好行动的参考点。正因如此,GRPO 根本不需要单独的 critic 模型。这节省了大量的计算量,并使过程更加高效。
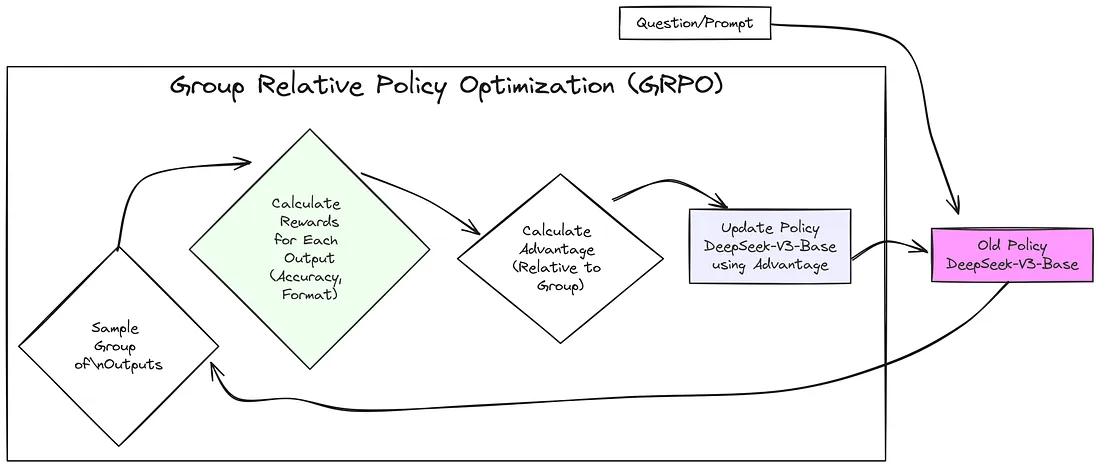
从向一个被称为 “Old Policy” 的模型提出一个问题或提示开始。GRPO 不是让旧策略只给出一个答案,而是指示旧策略针对同一个问题生成一组不同的答案。然后,对这些答案中的每一个进行评估,并给予一个奖励分数,以反映其优劣程度或符合期望的程度。
GRPO 通过将每个答案与它所在组中其他答案的平均质量进行比较,来计算该答案的 “Advantage”。优于平均水平的答案会得到正的优势值,而较差的答案则会得到负的优势值。关键在于,这一过程无需单独的 critic 模型即可完成。
然后,这些优势分数将被用于更新旧策略,使其在未来更有可能产生优于平均水平的答案。这个更新后的模型就成为新的 “Old Policy”,并且这个过程会不断重复,以迭代的方式改进模型。
5、GRPO 的目标函数
显然,在 GRPO 的背后,有着复杂的数学原理💀 简而言之,我们可以称其为 GRPO 背后的目标函数。
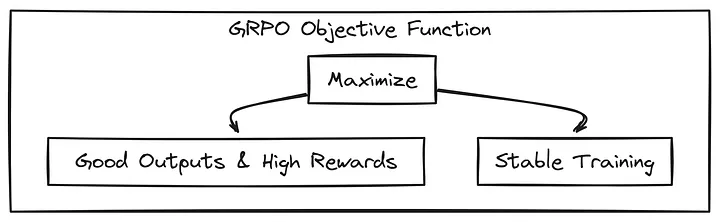
GRPO 的目标函数有两个目的,其一是给出优质的输出(高奖励),同时还要确保训练过程稳定,不会失控。

首先,“AverageResult[…]” 或者 “1/n[…]” 指的是评估在许多不同情形下的平均情况。我们向一个模型提出各种问题。对于每个问题,模型都会生成一组答案。通过研究这些针对众多问题的答案以及它们各自对应的答案组,我们就能计算出一个平均结果。
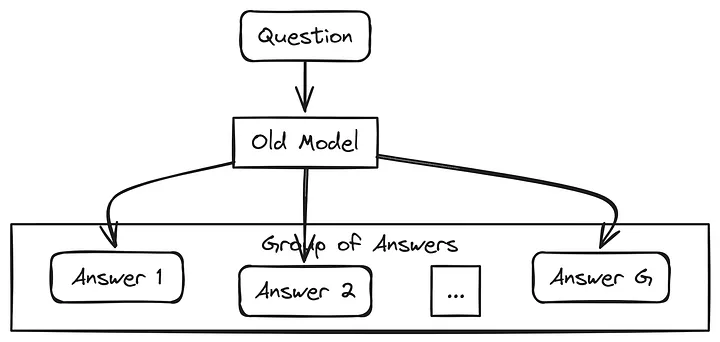
在这个过程中,将问题输入到一个旧模型中,该模型会生成多个答案(例如,答案1、答案2、……、答案G)。这些答案构成了一组,通过对不同问题的这组答案进行评估,我们得出平均结果。
“SumOf[..]” 或者 “∑[…]” 指的是对一组答案中的每个单独答案(例如,答案1、答案2、……、答案G)进行一次计算,然后将所有这些计算的结果相加。
接下来是 “RewardPart”。这是对模型给出优质答案进行奖励的部分。其内部要稍微复杂一些,所以让我们深入来看一下:

ChangeRatio 告诉我们,对于给出某个答案的可能性,新模型相较于旧模型是增加了还是减少了。具体来说,它会考量以下两点:
- Chance of Answer with New Model: 即新模型给出某个特定答案的可能性大小
- Chance of Answer with Old Model: 也就是旧模型给出同一个答案的可能性大小
接下来,Advantage 分数表明一个答案相较于同一组中的其他答案,是好多少还是差多少。它的计算方式如下:
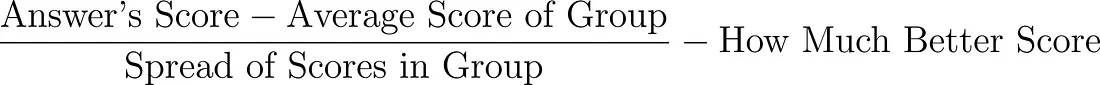
- Answer’s Score: 给予特定答案的奖励数值
- Average Score of Group: 该组中所有答案的平均奖励得分
- Spread of Scores in Group: 该组中各个答案得分之间存在多大的差异
Advantage 分数能告诉我们某个答案是否优于组内的平均水平,以及它具体好多少。
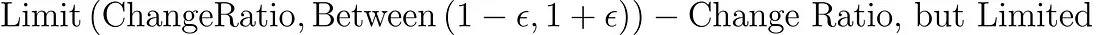
LimitedChangeRatio 是 ChangeRatio 的一个修正版本。它确保变化比率不会波动过大,从而使模型的学习过程保持稳定。这个限制由一个叫做 Epsilon 的小数值来决定,它能确保变化不会过于剧烈。
最后,SmallerOf[ … ] 函数会在两个选项中选取较小的值:
- ChangeRatio × Advantage: 某个答案出现可能性的变化值乘以其优势得分
- LimitedChangeRatio × Advantage: 原理相同,但使用的是有限变化比率
通过选择较小的值,模型能确保学习过程保持平稳,不会对性能上的大幅变化做出过度反应。其结果就是 “good answer reward”,这能鼓励模型在不过度补偿的情况下进行改进。
最后,我们减去 StayStablePart。这是为了防止新模型与旧模型之间产生过于巨大的变化。它并不复杂,但我们来深入看一下:

DifferenceFromReferenceModel 衡量的是 New Model 与 Reference Model(通常就是 Old Model)之间的差异程度。从本质上讲,它有助于评估新模型相较于之前的模型所做出的改变。
Beta 值控制着模型应在多大程度上与 Reference Model 保持接近。Beta 值越大,意味着模型会更优先保持与旧模型的行为和输出接近,从而避免出现过大的偏差。我们来形象地看一下:

所以简而言之,StayStablePart 确保了模型能够循序渐进地学习,而不会出现大幅度的突变。
6、DeepSeek R1 Zero 的奖励建模
既然我们已经了解了主要的理论概念,那就结合文本输入来了解一下创建 R1 Zero 所使用的奖励建模是如何运作的吧。
要记住,对于 R1 Zero 而言,没有使用复杂的神经网络来评判答案,而是采用了基于规则的奖励系统。
以我们的数学问题 “What is 2 + 3 * 4” 为例:
6.1、基于规则的检查
系统知道正确答案是 14。它会查看 DeepSeek V3(我们的强化学习智能体)生成的输出,并且会专门检查 <answer> 标签内的内容。

如果 <answer> 标签中包含 “14”(或者数值上等同的内容),将获得正奖励,比如说奖励值为 +1。如果答案错误,将获得 0 奖励,甚至可能是负奖励(不过,为了简单起见,在现阶段这篇论文重点考虑的是 0 奖励情况)。
6.2、格式奖励
但是,DeepSeek R1 Zero 也需要学习正确地组织其推理过程,为此可以使用 <think> 和 <answer> 标签。如果格式正确,会获得较小的奖励。
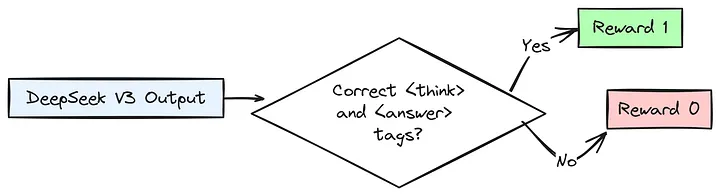
检查模型输出是否正确地将推理过程包含在 <think>…</think> 标签内,并且将最终答案包含在 <answer>…</answer> 标签内。
DeepSeek R1 论文明确提到,在 DeepSeek-R1-Zero 中避免使用神经奖励模型,以防止出现奖励操纵的情况,并在这个初始探索阶段降低复杂度。
7、奖励的训练模板
为了让奖励模型发挥作用,研究人员设计了一个特定的训练模板。这个模板就像一张蓝图,指导着 DeepSeek-V3-Base 在强化学习过程中如何组织其回复内容。
我们来看一下原始模板,并逐部分地分析它:
1
2
3
4
5
6
A conversation between User and Assistant. The user asks a question, and
the Assistant solves it. The assistant first thinks about the reasoning
process in the mind and then provides the user with the answer. The reasoning
process and answer are enclosed within <think> </think> and <answer> </answer>
tags respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: {prompt}. Assistant:
{prompt} 部分是我们填入数学问题的地方,比如 “What is 2 + 3 * 4?”。重要的部分是那些 <think> 和 <answer> 标签。这种结构化的输出对于研究人员日后深入了解模型的推理步骤来说是极其重要的。
当我们训练 DeepSeek-R1-Zero 时,我们会使用这个模板向它输入提示内容。对于我们所举的这个问题例子,输入内容看起来会是这样:
1
2
3
4
5
6
A conversation between User and Assistant. The user asks a question, and
the Assistant solves it. The assistant first thinks about the reasoning
process in the mind and then provides the user with the answer. The reasoning
process and answer are enclosed within <think> </think> and <answer> </answer>
tags respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: What is 2 + 3 * 4?. Assistant:
并且我们期望模型生成符合该模板的输出,例如:
1
2
3
4
5
6
7
<think>
Order of operations:
multiply before add. 3 * 4 = 12. 2 + 12 = 14
</think>
<answer>
14
</answer>
有趣的是,DeepSeek 团队有意让这个模板保持简洁,并且专注于结构方面,而非告诉模型如何进行推理。
8、DeepSeek R1 Zero 的强化学习训练过程
尽管论文没有明确说明强化学习预训练的确切初始数据集是什么,但我们推测它应该是以推理为重点的。
他们所做的第一步是使用 old policy(即在强化学习更新之前的 DeepSeek-V3-Base)生成多种可能的输出。在一次训练迭代中,我们假设 GRPO 采样了一组数量 G = 4 的输出。
例如,对于我们的文本输入 “What is 2 + 3 * 4?”,模型产生了以下四种输出:
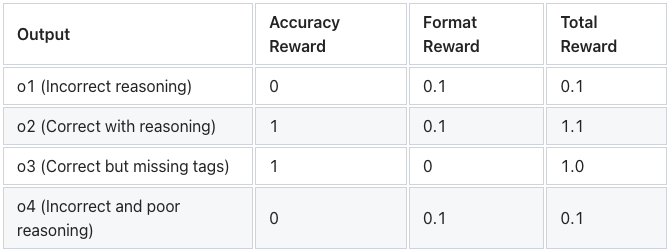
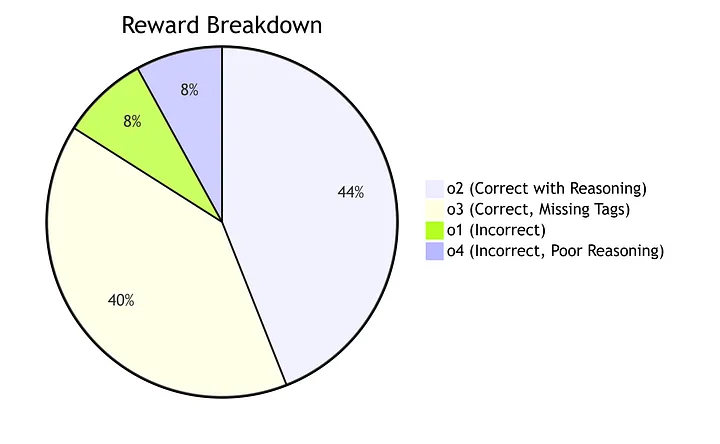
- o1:
<think> 2 + 3 = 5,5 * 4 = 20 </think> <answer> 20 </answer>(运算顺序错误) - o2:
<think> 3 * 4 = 12,2 + 12 = 14 </think> <answer> 14 </answer>(正确) - o3:
<think> 14 </answer>(正确,但缺少标签) - o4:
<think> ……一些无意义的推理内容…… </think> <answer> 7 </answer>(错误且推理质量差)

每个输出都将接受评估,并根据正确性和推理质量来赋予相应的奖励。
为了引导模型进行更好的推理,基于规则的奖励系统开始发挥作用。每个输出都会基于以下方面被赋予奖励:
- 准确性奖励:答案是否正确。
- 格式奖励:推理步骤使用
<think>标签的格式是否正确。
假设奖励的分配情况如下:
模型应该学会倾向于获得更高奖励的输出,同时降低生成错误或不完整输出的概率。
为了确定每个输出对模型性能的提升或降低程度,我们使用奖励值来计算优势。这种优势通过强化更好的输出来帮助优化策略。
为此,我们首先来计算首次奖励的平均值。

标准差(近似值) = 0.5,现在来计算每个输出的优势。


输出 o2 和 o3 获得了正的优势值,这意味着应该鼓励生成这类输出。输出 o1 和 o4 获得了负的优势值,这意味着应该抑制生成这类输出。
然后,GRPO 利用计算出的优势值来更新策略模型(DeepSeek-V3-Base),以增加生成具有高优势值输出(如 o2 和 o3)的概率,并降低生成具有低优势值或负优势值输出(如 o1 和 o4)的概率。
更新操作会基于以下几点来调整模型的权重:
- 策略比率: 在新策略和旧策略下生成某个输出的概率之比
- 裁剪机制: 防止出现过大的更新,以免导致训练过程不稳定
- KL 散度惩罚项: 确保更新不会使模型与原始模型偏离太远

这确保了在接下来的迭代中,模型更有可能生成正确的推理步骤,同时减少错误或不完整的回复。
因此,强化学习(RL)是一个迭代的过程。上述步骤会使用不同的推理问题重复数千次。每一次迭代都会逐步提升模型以下方面的能力:
- 按正确的运算顺序进行运算
- 提供符合逻辑的推理步骤
- 始终如一地使用恰当的格式
整个训练循环如下所示:
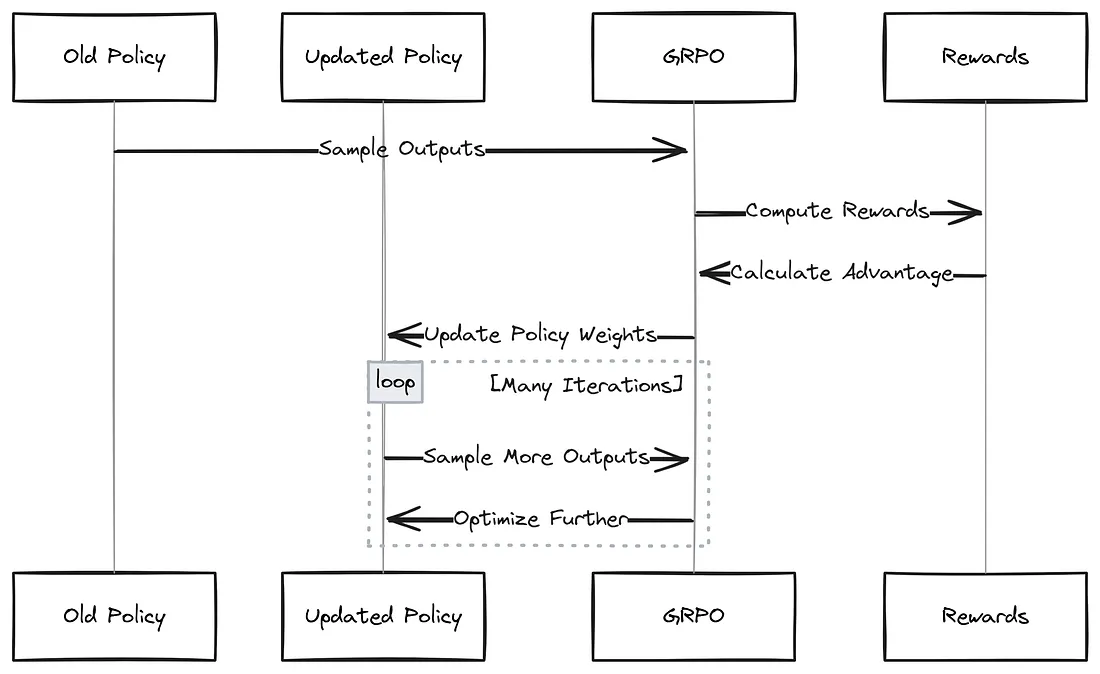
随着时间的推移,该模型会从自身的错误中学习,在解决推理问题方面变得更加准确和高效。🚀
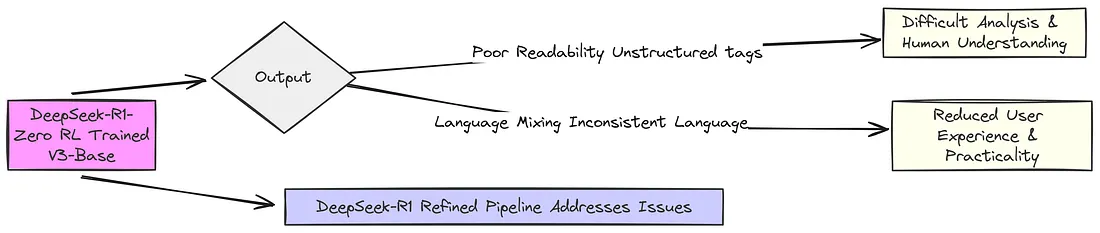
9、R1 Zero 的两个主要问题
在基于 V3 模型通过强化学习训练过程创建了 DeepSeek-R1 Zero 之后,研究人员发现,经过训练的模型在推理测试中表现非常出色,甚至在诸如 2024 年美国数学邀请赛(AIME)等任务上的得分与更先进的模型(如 OpenAI-01–0912)相近。这表明,使用强化学习(RL)来促进语言模型的推理能力是一种很有前景的方法。
但他们也注意到,DeepSeek-R1-Zero 存在一些关键问题,这些问题需要解决,才能在现实世界中应用以及开展更广泛的研究。
DeepSeek 的研究人员表示,该模板是特意设计得简单且侧重于结构方面。它避免对推理过程本身施加任何特定于内容的限制。例如,它没有说:
- “你必须使用逐步推理的方式”(它只是提到 “推理过程”,让模型自行定义其含义)
- “你必须使用反思性推理”
- “你必须使用特定的解决问题的策略”
主要的问题是,<think> 标签内的推理过程很难读懂,这使得人类很难理解和分析。
另一个问题是语言混合问题,当被问到多语言问题时,该模型有时会在同一个回复中混合使用多种语言,从而导致输出不一致且令人困惑。比如说,如果你用西班牙语向它提问,突然之间,它的 “思考” 内容会是英语和西班牙语的杂乱混合,并不十分完善!这些杂乱的推理和语言混淆问题显然成了阻碍。
这就是他们将最初的 R1 Zero 模型改进为 R1 模型的两个主要原因。
在下一部分,我们将探讨他们是如何将 R1 Zero 模型改进为 R1 模型的,这提升了模型的性能,使其在表现上超越了其他所有模型,无论是开源的还是闭源的模型。
10、冷启动数据
因此,为了解决 R1 Zero 模型存在的问题,并真正让 DeepSeek 实现合理的推理,研究人员进行了冷启动数据收集,并采用了有监督的微调方法。
你可以把这想象成在进行真正高强度的强化学习训练之前,为模型打下良好的推理基础。基本上,他们想教会 DeepSeek-V3 Base 什么是好的推理,以及如何清晰地呈现推理过程。
10.1、基于长思维链的少样本提示法
他们为 DeepSeek-V3 基础模型提供了一些问题示例,以及非常详细的、逐步的解决方案,这种方案被称为思维链(CoT)。其目的是让模型通过示例进行学习,并开始模仿这种逐步推理的方式。
让我们直观地了解一下这种基于示例的学习方式:
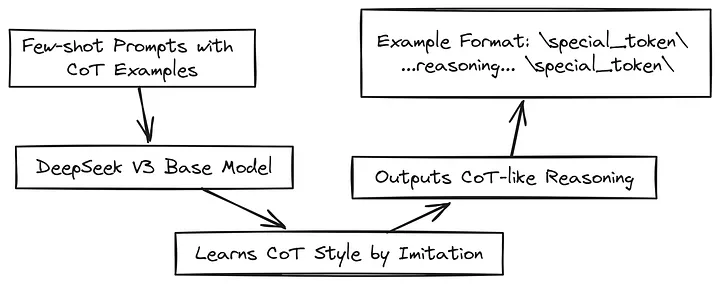
对于我们的示例问题 What is 2 + 3 * 4?,他们可能会展示像这样的提示内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
Problem Examples with Solutions:
Problem: What's the square root of 9 plus 5?
Solution: | special_token | First, find the square root of 9, which is 3.
Then, add 5 to 3. 3 + 5 equals 8. | special_token | Summary: The answer is 8.
Problem: Train travels at 60 mph for 2 hours, how far?
Solution: | special_token | Use the formula: Distance = Speed times Time.
Speed is 60 mph, Time is 2 hours. Distance = 60 * 2 = 120 miles.
| special_token | Summary: Train travels 120 miles.
Problem: What is 2 + 3 * 4?
Solution:
那些 | special_token | 的东西只是用于将推理步骤和总结区分开来的标识,这样能让模型清楚地学习其中的结构。
在看过这些示例之后,模型应该学会以类似的格式给出答案,比如对于 What is 2 + 3 * 4? 这个问题,答案可能是这样的:
1
2
3
| special_token | Following order of operations (PEMDAS/BODMAS),
do multiplication before addition. So, first calculate 3 * 4 = 12.
Then, add 2 to 12. 2 + 12 = 14. | special_token | Summary: The answer is 14.
10.2、直接提示法
他们收集数据的另一种方式是直接向模型提出要求,不仅要让模型解决问题,还要让它清晰地逐步展示推理过程,然后对答案进行再次检查。
这旨在促使模型进行更细致、更周全的问题解决。
对于 What is 2 + 3 * 4? 这个问题,提示内容可能是:
1
2
Problem: Solve this, show reasoning step-by-step, and verify:
What is 2 + 3 * 4?
并且他们确实期望得到一个既包含推理步骤又包含验证部分的输出结果:
1
2
3
4
5
6
7
| special_token | Reasoning: To solve 2 + 3 * 4, I need to use order of
operations. Multiplication comes before addition.
Step 1: Calculate 3 * 4 = 12.
Step 2: Add 2 to the result from step 1: 2 + 12 = 14.
Verification: Checking order of operations again, yes, multiplication
is before addition. Calculation looks right.
| special_token | Summary: The answer is 14.
10.3、后处理优化
他们甚至利用了已经训练好的 R1 Zero 模型的输出结果。尽管 R1 Zero 存在一些问题,但它还是具备一定的推理能力。所以,他们获取了 R1 Zero 的输出,然后让人工注释员对这些输出进行完善,使其更简洁、更有条理,并纠正其中的任何错误。
例如,一个杂乱的 R1 Zero 输出可能是这样的:
1
2
<think> ummm... multiply 3 and 4... get 12... then add 2...</think>
<answer> 14 </answer>
然后,人类会对其进行优化,使其更加清晰,格式也更加规范:
1
2
3
4
5
| special_token | Reasoning: To solve this, we use order of operations,
doing multiplication before addition.
Step 1: Multiply 3 by 4, which is 12.
Step 2: Add 2 to the result: 2 + 12 = 14.
| special_token | Summary: The answer is 14.
对优化过程进行可视化的工作原理如下:

他们最终得到的冷启动数据非常出色,原因如下:
- 高质量的推理示例: 每个示例都展示了良好的、逐步的推理过程
- 格式一致且易于阅读:
| special_token |格式使所有内容保持统一,并且易于处理 - 人工检查: 他们确保筛选掉任何不良示例,因此数据干净且可靠
在获得这些冷启动数据后,他们进行了有监督的微调(SFT)。
11、有监督的微调
第一阶段有监督微调的核心思想是使用监督学习来教会 DeepSeek-V3-Base 如何生成高质量、结构化的推理输出。
基本上,我们向模型展示了许多良好推理的示例,并要求它学习模仿这种方式。
对于有监督的微调,我们需要将冷启动数据格式化为输入-目标对。对于数据集中的每个推理问题,我们创建如下的一对内容:
输入 = 提示或问题描述本身
1
User: What is 2 + 3 * 4? Assistant:
这就是我们输入到模型中的内容,而我们的目标输出则是对应的结构良好的推理过程和答案。
1
2
| special_token | According to the order of operations (PEMDAS/BODMAS) ...
Summary: The answer is 14.
这是我们希望模型学习生成的理想输出。
我们在告诉模型:
当你看到这个输入(问题)时,我们希望你能生成这个目标输出(合理的推理过程和答案)。
与其用详细的文字来解释,让你难以理解,不如我们先将其可视化,以便更轻松地解释 SFT 的相关内容。
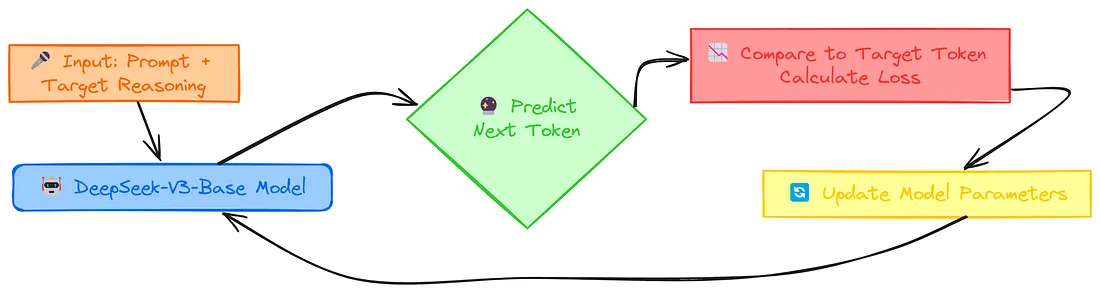
SFT 过程从 Input: Prompt + Target Reasoning 开始,在此过程中我们会提供一个问题以及一个结构化的推理示例。这会训练模型(DeepSeek-V3-Base Model)生成结构良好的回复。
在 Predict Next Token 阶段,模型会生成推理序列中的下一个词。在 Compare to Target Token (Calculate Loss) 环节,会使用损失函数将生成的词与实际的下一个词元进行比较。损失值越高,意味着预测结果与正确词元的偏差越大。
在 Update Model Parameters 阶段,通过反向传播和优化器来调整模型的权重,以提高其预测能力。这个过程会循环往复,对许多 输入-目标对 重复进行操作,每次迭代都能逐步提升模型的结构化推理能力。
12、面向推理的强化学习
研究人员已经在 SFT 阶段对 DeepSeek V3 进行了推理方面的训练,但为了真正提升它的推理技能,他们引入了 面向推理的学习!
这一步是对经过监督微调的 DeepSeek V3 模型进一步优化,通过强化学习使其表现更出色。
他们使用了与之前相同的 GRPO 算法,但在这个阶段真正的升级之处在于奖励系统。他们加入了一项新的且极其重要的内容:语言一致性奖励!
还记得 R1 Zero 有时会在语言方面出现混淆,甚至开始将不同语言混用的情况吗?为了解决这个问题,他们专门设置了语言一致性奖励。其原理很简单,如果你用英语提出一个问题,我们希望推理过程和答案也都用英语呈现。
让我们直观地看一下这个语言一致性奖励的计算过程:
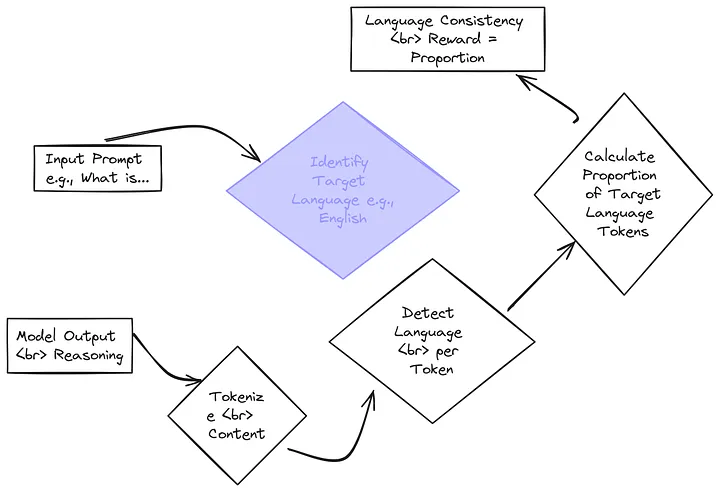
为了理解上面的图表,让我们回顾一下之前的示例输出 o1 和 o2,看看随着这个新的语言一致性奖励的引入,奖励情况会如何变化。为简便起见,我们假设目标语言是英语。
让我们看看这些奖励在我们的示例输出中是如何体现的。考虑第一个输出 o1,它错误地计算了 “2 + 3 * 4”,但它是以英语呈现其有缺陷的推理过程的:
1
<think> 2 + 3 = 5, 5 * 4 = 20 </think> <answer> 20 </answer>
对于这种情况,由于答案是错误的,所以准确性奖励自然为 0。然而,因为假设推理过程完全使用目标语言(在这个例子中是英语),所以它会得到 1 的语言一致性奖励。
当我们计算强化学习阶段的总奖励时,我们会综合考虑这些因素。如果我们给准确性奖励赋予权重 1,给语言一致性奖励赋予较小的权重,比如说 0.2,那么 o1 的总奖励就会是:
1
2
3
Total Reward = (1 * Accuracy Reward) + (0.2 * Language Consistency Reward)
(1 * 0) + (0.2 * 1) = 0.2
现在考虑输出 o2,它正确地解决了问题,并且也是用英语进行推理的:
1
<think> 3 * 4 = 12, 2 + 12 = 14 </think> <answer> 14 </answer>
这个输出因为答案正确而获得了完美的准确性奖励 1 分。假设它的推理过程也完全是用英语进行的,那么它还能获得 1 分的语言一致性奖励。使用和之前相同的权重,o2 的总奖励为:
1
(1 * 1) + (0.2 * 1) = 1.2
请注意,即使对于正确答案,语言一致性奖励也会略微提高总奖励分数;并且只要错误答案 o1 保持了语言一致性,它也能获得一个小小的正奖励分数。
这个强化学习(RL)训练循环和我们之前看到的 DeepSeek R1 Zero 的训练循环是一样的:
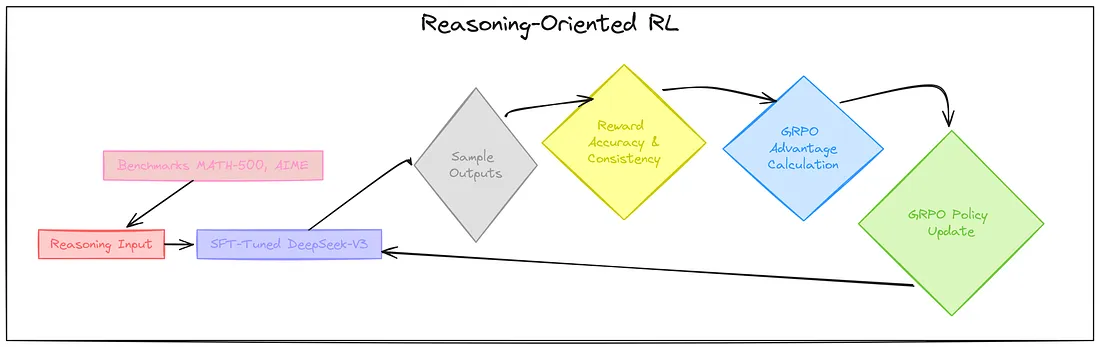
- 生成多个输出
- 优化奖励机制,包括语言一致性奖励
- 使用 GRPO 来估计优势
- 训练模型以偏好具有高优势的输出
- 重复这个过程!
13、拒绝采样
对于推理数据,DeepSeek 希望获取绝对最佳的示例来进一步训练模型。为了做到这一点,他们使用了一种称为拒绝采样的技术。
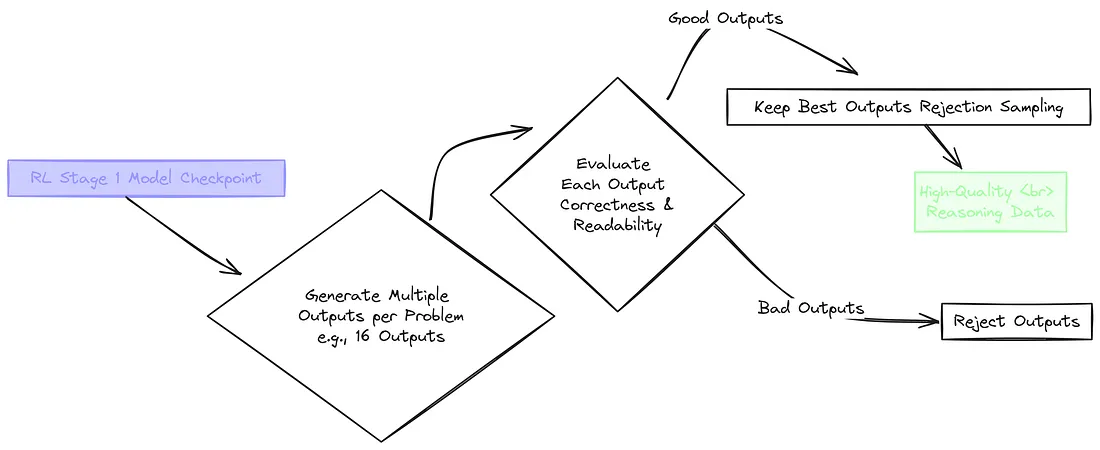
为了优化推理数据,DeepSeek 使用了 拒绝采样 的方法。对于 “What is 2 + 3 * 4?” 这个问题,他们会从前一阶段的模型中生成许多输出结果。想象一下得到像 <answer>20</answer>(错误)和 <answer>14</answer> <think>…</think>(正确且有推理过程)这样的输出。
然后,他们会评估每个输出的正确性(答案为 “14” 是正确的)以及推理过程的可读性。只有那些最佳的、答案正确且推理合理的输出会被保留下来,其他的则会被舍弃。
对于复杂的推理,会使用一个生成式奖励模型来评判推理质量。严格的筛选条件会剔除那些语言混用、推理杂乱无章或者包含不相关代码的输出。通过这个过程,得到了大约 60 万个高质量的推理样本。
除了经过优化的推理数据,他们还添加了非推理数据(约 20 万个样本)来提升模型的通用技能,比如写作、问答、翻译等等。对于一些复杂任务,有时还会使用思维链(Chain-of-Thought)的方式。
最后,在 SFT 的第二阶段,会使用下一个词元预测的方法,在合并后的数据集(优化后的推理数据加上非推理数据)上对之前的模型检查点(checkpoint)进行训练。这个阶段会利用拒绝采样得到的顶级示例进一步提升模型的推理能力,同时让模型能够更好地适应更广泛的任务,并且保持对用户友好的特性。
“What is 2 + 3 * 4?” 这个现在已经是经过完美优化的推理示例,也成为了这个训练数据的一部分。
这就是拒绝采样,我们剔除了质量欠佳的样本,只保留最好的样本,从而生成高质量的训练数据。
14、适用于所有场景的强化学习
在完成了 SFT 的第二阶段后,DeepSeek V3 已经能够进行推理、保持语言的一致性,甚至在处理一般任务方面也表现得相当不错!但是,为了真正让它成为顶级的人工智能助手,研究人员进行了最后一步调整,使其与人类价值观保持一致。这就是适用于所有场景的强化学习(RL 第二阶段)的使命!可以把这看作是让 DeepSeek R1 真正安全可靠的最后一道打磨工序。
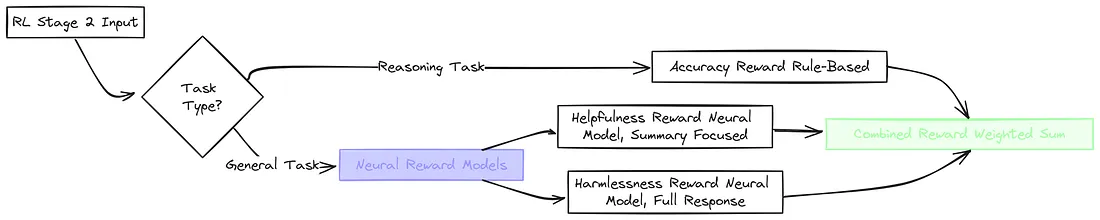
对于我们的例子 “What is 2 + 3 * 4?”,虽然准确性奖励仍然会强化正确答案,但现在的奖励系统还会考虑以下方面:
- 有用性,评估(如果生成了的话)总结内容是否除了答案之外还提供了有用的背景信息
- 无害性,检查整个输出内容是否安全且无偏见。这些通常由在人类偏好数据上训练的独立奖励模型来评估
最终的奖励信号变成了准确性、有用性和无害性得分的加权组合。
现在,训练数据包括:
- 多样化的内容,其中有推理问题
- 一般性的问答提示
- 写作任务
- 以及偏好对数据,在这种数据中人类会指出两个模型输出中哪一个在有用性和无害性方面表现更好
训练过程遵循一个迭代的强化学习循环(很可能使用 GRPO),根据来自这些多样化数据的综合奖励信号来优化模型。
经过许多次的训练迭代后,模型得到了优化,在推理性能和一致性(有用性/无害性)之间取得了良好的平衡。一旦达到了这种平衡,就会在流行的基准数据集上对模型进行评估,并且它的表现会超过其他模型。
然后,他们高度优化版本的最终检查点模型就被命名为 DeepSeek-R1。
15、知识蒸馏
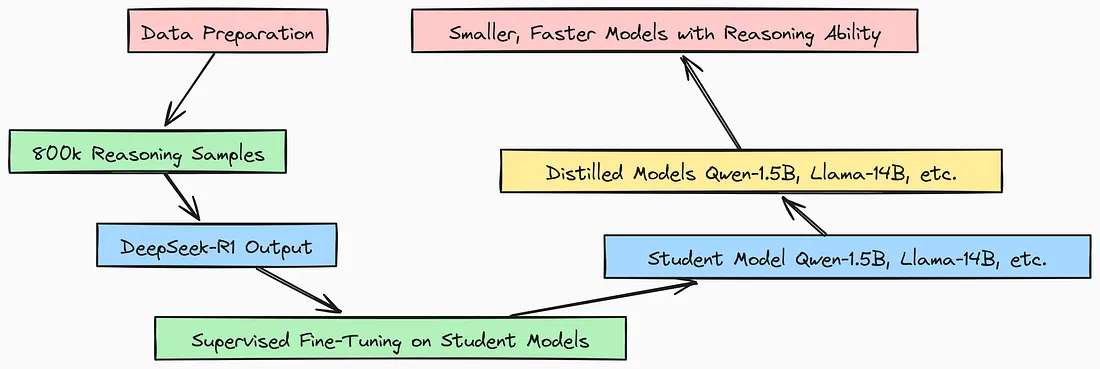
在 DeepSeek 成功创建了性能出色的 DeepSeek R1 之后,他们进一步将较大规模的模型进行蒸馏,为社区打造出了性能有所提升的较小规模模型。以下是蒸馏过程的工作原理:
- 数据准备: 收集 80 万个推理样本
- DeepSeek R1 的输出: 对于每个样本,教师模型(DeepSeek R1)的输出将作为学生模型的目标输出
- 监督微调(SFT): 学生模型(例如,Qwen-1.5B、Llama-14B)会在这 80 万个样本上进行微调,使其输出与 DeepSeek R1 的输出相匹配
- 蒸馏后的模型: 现在,学生模型已被蒸馏成较小的版本,但保留了 DeepSeek R1 的大部分推理能力
- 结果: 你得到了更小、运行速度更快且具有良好推理能力的模型,可随时进行部署
