1、Qwen 1
Qwen 1 发布于 2023 年 8 月,Qwen 是一个全面的大型语言模型系列,涵盖了具有不同参数数量的不同模型,包括 Qwen 基础预训练语言模型和 Qwen-Chat,后者是通过人类对齐技术微调的聊天模型。
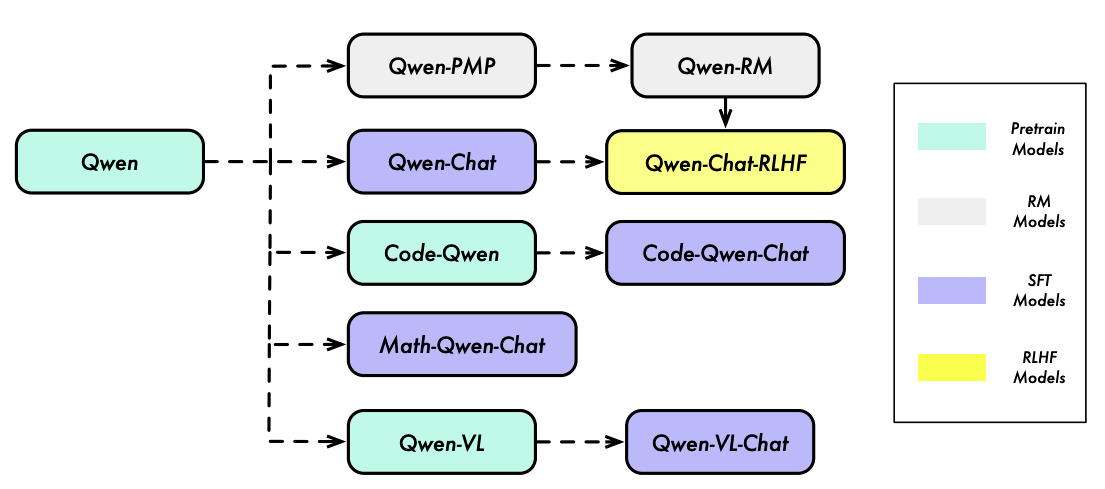
1.1、预训练
1.1.1、数据
为确保预训练数据的质量,对于公共网络数据,从 HTML 中提取文本并使用语言识别工具来确定语言。为了增加数据的多样性,采用去重技术,包括规范化后的精确匹配去重和使用 MinHash 和 LSH 算法的模糊去重。为了过滤掉低质量数据,结合使用基于规则的方法和基于机器学习的方法。具体来说,使用多个模型对内容进行评分,包括语言模型、文本质量评分模型以及识别潜在冒犯性或不适宜内容的模型。为了进一步提升数据质量,选择性地对某些来源的数据进行过采样,以确保模型在多样化的高质量内容上得到训练。为了进一步提升模型的性能,将高质量的指令数据纳入到预训练过程中。最后,构建了一个高达 3万亿 个词元的数据集。
1.1.2、分词
与 GPT-3.5 和 GPT-4 的做法一致,采用字节对编码(BPE)作为分词方法。从开源的快速 BPE 分词器 tiktoken 开始,并选择 cl100k 基础词汇表作为起点。为了提高模型在多语言下游任务上的表现,特别是在中文方面,在词汇表中增加了常用的汉字和词语,以及其他语言的相应内容。此外,将数字拆分为个位数。最终的词汇表大小约为 152K。
1.1.3、架构
Qwen 1 采用经过修改的 Transformer 架构设计:
- 嵌入层与输出投影层: 选择非绑定嵌入方式,而非将输入嵌入层和输出投影层的权重绑定。这一决策是为了在牺牲一定内存成本的前提下,获得更好的性能
- 位置嵌入:选择旋转位置嵌入(RoPE)作为在模型中融入位置信息的首选方案。为了优先保证模型性能并实现更高的准确率,选择使用 FP32 精度来表示逆频率矩阵,而非 BF16 或 FP16
- 偏置项:在大多数层中移除了偏置项,但在注意力机制的
QKV层添加了偏置项,以增强模型的外推能力 - 预归一化与RMS归一化:与后归一化相比,预归一化可以提高训练的稳定性。此外,采用 RMS 归一化取代了传统层归一化技术,在保持性能相当的同时提高了效率
- 激活函数:选择 SwiGLU 作为激活函数,它是 Swish 激活函数和门控线性单元(GLU)的结合。基于 GLU 的激活函数总体上优于其他基准选项,如高斯误差线性单元(GeLU)。此外,将前馈网络(FFN)的维度从隐藏层大小的 4 倍缩减至隐藏层大小的 $\frac{8}{3}$ 倍
1.1.4、训练
训练 Qwen 采用自回归语言建模的标准方法,训练上下文长度为 2048,为了创建数据批次,对文档进行打乱和合并,然后将它们截断至指定的上下文长度。为了提高计算效率并减少内存使用,在注意力模块中采用了闪存注意力机制(Flash Attention)。模型采用标准优化器 AdamW 进行预训练优化,超参数设置为 $\beta_1 = 0.9$、$\beta_2 = 0.95$ 以及 $\epsilon = 10^{-8}$。针对每个模型规模使用指定峰值学习率的余弦学习率调度策略。学习率会衰减至峰值学习率的 10% 作为最小学习率。为了保证训练的稳定性,所有模型均采用 BFloat16 混合精度进行训练。
1.1.5、上下文长度扩展
随着上下文长度的增加,Transformer 模型的注意力机制计算复杂度呈二次方增长,这会导致计算量和内存成本急剧上升。Qwen 仅在推理阶段应用相关技术以扩展模型的上下文长度,具体的,采用 NTK 感知插值 以一种无需训练的方式调整 RoPE 的基数,从而防止高频信息丢失。这与位置插值不同,位置插值会对旋转位置编码(RoPE)的每个维度进行同等缩放。为进一步提升性能,通过动态 NTK 感知插值,按块动态改变缩放比例,避免性能严重下降,有效扩展 Transformer 模型的上下文长度。
Qwen 还集成了两种注意力机制: LogN-Scaling 和 窗口注意力(window attention)。 LogN-Scaling 根据上下文长度与训练长度的比例对查询和键的点积进行重新缩放,确保随着上下文长度的增加,注意力值的熵保持稳定。窗口注意力将注意力限制在一个有限的上下文窗口内,防止模型关注距离过远的词元。
模型的长上下文建模能力在不同层之间存在差异,与较高层相比,较低层在上下文长度扩展方面更为敏感。基于这一观察结果,Qwen 为每一层分配不同的窗口大小,较低层使用较短的窗口,较高层使用较长的窗口。
1.2、对齐
使用对齐技术,如监督微调和基于人类反馈的强化学习,可以显著提高语言模型参与自然对话的能力。
1.2.1、监督微调
与预训练一致,SFT(监督微调)将下一个词的预测作为的训练任务,并对系统和用户的输入应用了损失掩码。模型的训练过程使用 AdamW 优化器,其超参数设置为:$\beta_{1}$ 为 0.9,$\beta_{2}$ 为 0.95,$\epsilon$ 为 $10^{-8}$。序列长度限制为 2048,批量大小为 128。模型总共训练 4000 步,其中前 1430 步学习率逐步上升,达到峰值 $2 \times 10^{-6}$。为了防止过拟合,权重衰减值设为 0.1,dropout 设置为 0.1,并使用梯度裁剪,限制为 1.0。
1.2.2、人类反馈的强化学习
1.2.2.1、奖励模型
RM 数据集由样本对组成,每个样本对包含针对单个查询的两个不同响应及其相应的偏好。
1.2.2.2、强化学习
近端策略优化(PPO)过程涉及四个模型:策略模型、价值模型、参考模型和奖励模型。
在启动 PPO 流程之前暂停策略模型的更新,仅专注于对价值模型进行 50 步的更新。这种方法能确保价值模型有效适应不同的奖励模型。
在PPO操作期间,采用为每个查询同时采样两个回复的策略。将 KL 散度系数设置为 0.04,并基于滑动均值对奖励进行归一化处理。
策略模型和价值模型的学习率分别设为 $1 \times 10^{-6}$ 和 $5 \times 10^{-6}$。为增强训练稳定性,采用值损失裁剪,裁剪值设为 0.15。在推理阶段,策略的核采样概率(top-p)设置为 0.9。虽然此时的熵比 top-p 设为 1.0 时略低,但奖励增长更快,最终在相似条件下能持续获得更高的评估奖励。
此外,Qwen 1 引入了预训练梯度来减轻对齐代价。在使用该特定奖励模型时,KL 惩罚在非严格代码或数学性质的基准测试(如常识知识和阅读理解测试)中足以抵消对齐代价。为确保预训练梯度的有效性,相比 PPO 数据,必须使用大量的预训练数据。此外,该系数值过大可能会严重阻碍模型向奖励模型对齐,最终损害最终的对齐效果;而该系数值过小对降低对齐代价的作用则微乎其微。
2、Qwen 2
Qwen 2 发布于 2024 年 6 月,是一系列基于 Transformer 架构并使用下一个词元预测进行训练的大型语言模型。该系列模型涵盖了 4 个基础模型,参数数量分别为 5 亿、15 亿、70 亿和 720 亿,以及一个拥有 570 亿参数的专家混合(MoE)模型,该模型在处理每个词元时会激活 140 亿个参数。所有模型均在一个高质量、大规模的数据集上进行预训练,该数据集包含超过 7 万亿个词元,涵盖广泛的领域和语言。
2.1、分词器
与 Qwen 1 采用基于字节级字节对编码的相同分词器,所有规模的模型都使用了一个通用词表,该词表包含 151,643 个常规词元以及 3 个控制词元。
2.2、模型架构
Qwen2 是基于 Transformer 架构的大型语言模型,其特点是采用带因果掩码的自注意力机制。具体而言,该系列包括 4 种规模的稠密语言模型以及一个混合专家(MoE)模型。
2.2.1、稠密模型
Qwen2 稠密模型的架构由多个 Transformer 层组成,每个层都配备因果注意力机制和前馈神经网络(FFN)。
2.2.1.1、分组查询注意力
Qwen 2 采用分组查询注意力(GQA),而非传统的多头注意力(MHA)。GQA在推理过程中优化了键值(KV)缓存的使用,显著提高了吞吐量
2.2.1.2、结合 YARN 的双块注意力
通过双块注意力(DCA)扩大 Qwen 2 的上下文窗口,其将长序列分割成易于处理长度的块。如果输入可以在一个块内处理,DCA 产生的结果与原始注意力相同。否则,DCA 有助于有效捕捉块内和块间词元之间的相对位置信息,从而提升长上下文性能。此外,采用 YARN 对注意力权重进行重新缩放,以实现更好的长度外推。
Qwen 2 延续 Qwen 1 的做法,使用 SwiGLU 作为激活函数,旋转位置嵌入(RoPE)进行位置嵌入,在注意力机制中使用 QKV 偏置,并采用 RMSNorm 和预归一化来确保训练稳定性。
2.2.2、专家混合模型
Qwen 2 MoE 模型的架构中,MoE FFN(混合专家前馈网络)作为原始 FFN 的替代,由 $n$ 个独立的 FFN 组成,每个 FFN 作为一个专家。每个 token 根据由门控网络 $G$ 分配的概率,指派给特定的专家 $E_{i}$ 进行计算:
\[p = \text{softmax}(G(x))\] \[y = \sum_{i \in \text{topk}(p)} p_i E_i(x)\]- 专家粒度
- MoE 模型与密集模型的主要结构差异在于,MoE 层包含多个 FFN,每个 FFN 作为一个单独的专家。因此,从密集架构过渡到 MoE 架构的一种简单策略是将每个专家的参数设置为原始密集模型中单个 FFN 的参数。与此不同,Qwen 2 MoE 采用了精细粒度的专家,创建了较小规模的专家,同时激活更多的专家。考虑到专家参数的总量和激活参数数目相等,精细粒度的专家提供了更丰富的专家组合。通过利用这些精细粒度的专家,Qwen2 MoE 能够实现更多样化和动态的专家使用,从而提升整体性能和适应性
- 专家路由
- 专家路由机制的设计对于提高 MoE 模型的性能至关重要。Qwen 2 采用了在 MoE 层中集成共享专家和路由专用专家,使得共享专家可以在多个任务中应用,同时将其他专家保留供特定路由场景使用。引入共享专家和专用专家为开发 MoE 路由机制提供了更具适应性和高效性的方法
- 专家初始化
- Qwen 2 以类似于 “upcycling” 的方法初始化专家,利用密集模型的权重。有所区别的是,Qwen 2 强调在精细粒度的专家之间进行多样化,以增强模型的表示能力。给定指定的专家中间尺寸 $h_E$、专家数量 $n$ 和原始 FFN 中间尺寸 $h_{FFN}$,将 FFN 复制 $\lceil \frac{n \times h_E}{h_{FFN}} \rceil$ 次,确保了与指定的专家数量兼容,同时能够适应任意的专家中间尺寸。为了促进每个 FFN 副本中的多样性,Qwen 2 沿着中间维度对参数进行打乱。确保即使在不同的 FFN 副本中,每个精细粒度的专家也能展现出独特的特征。随后,这些专家从 FFN 副本中提取出来,剩余的维度则被丢弃。对于每个精细粒度的专家,随机重新初始化 50% 的参数。这一过程为专家初始化引入了额外的随机性,可能增强了模型在训练过程中的探索能力
2.3、预训练
2.3.1、预训练数据
Qwen 2 预训练数据量从 Qwen1.5 中的 3 万亿 tokens 扩展到了 7 万亿 tokens。尝试进一步放宽质量阈值,最终得到了一个包含 12 万亿 tokens 的数据集。在这个数据集上训练的模型在性能上并未显著超越使用 7 万亿 tokens 的数据集的模型。推测增加数据量并不一定有利于模型的预训练,考虑到训练成本选择使用质量更高的 7 万亿 tokens 数据集来训练更大的模型
与 “upcycling” 原则一致,MoE 模型额外获得了 4.5 万亿 tokens 的预训练。高质量的多任务指令数据被整合到 Qwen2 的预训练过程中,以增强模型的上下文学习能力和指令跟随能力。
2.3.2、长上下文训练
为了提升 Qwen 2 的长上下文能力,在预训练的收尾阶段将上下文长度从 4096 增加到 32768,此次扩展还伴随着大量高质量、长篇数据的引入。结合这些改进,将 RoPE 的基础频率从 10,000 调整至 1,000,000,以优化长上下文场景下的性能。
为了充分发挥模型的长度外推潜力,Qwen 2 采用了 YARN 机制和双块注意力机制。这些策略使模型能够在处理长达 131,072 个令牌的序列时保持高性能,初步实验中极小的困惑度下降便是证明。
2.4、后训练
后训练数据(post-training data)的构建旨在增强模型在广泛领域的能力,包括编码、数学、逻辑推理、指令遵循和多语言理解,以及确保模型的生成结果符合人类价值观,使其有用、诚实和无害。与传统的依赖大量人工监督的方法不同,Qwen 2 专注于通过最小化人工标注来实现可扩展的对齐。
2.4.1、后训练数据
后训练数据主要由两部分组成:演示数据 $\mathcal{D}={(x_{i},y_{i})}$ 和偏好数据 $\mathcal{P}={(x_{i},y_{i}^{+},y_{i}^{-})}$,其中 $x_{i}$ 表示指令,$y_{i}$ 表示一个满意的响应,而 $y_{i}^{+}$ 和 $y_{i}^{-}$ 是对 $x_{i}$ 的两个响应,$y_{i}^{+}$ 被认为是优于 $y_{i}^{-}$ 的选择。集合 $\mathcal{D}$ 用于监督微调(SFT),而集合 $\mathcal{P}$ 用于强化学习从人类反馈(RLHF)。
数据构建的两步过程:
-
协作数据标注
自动本体提取: 应用 InsTag 细粒度标签器,从大规模指令语料库中提取底层本体,并进行手动细化以确保提取的本体的准确性
指令选择: 每个带有标签的指令都会根据标签多样性、语义丰富性、复杂性和意图完整性进行评估。基于这些标准,选择一组具有代表性的指令
指令进化: 为了丰富指令数据集,采用自进化策略提示 Qwen 模型向现有指令添加约束或要求,从而增加其复杂度,并确保数据集中有多样化的难度级别
人工标注: 通过多种生成策略和不同规模的 Qwen 模型获取指令的多个响应。标注者根据偏好对这些响应进行排名,确保最佳响应符合既定标准,从而产生演示数据和偏好数据
-
自动化数据合成
拒绝采样: 对于具有明确最终答案的数学或类似任务,采用拒绝采样来提高解决方案的质量。LLMs 需针对每条指令生成多个回复,即推理路径。能得出准确结论且被模型认为合理的路径将被保留用作示范数据,偏好数据则通过对比正确与错误路径生成
执行反馈: 对于编码任务,LLMs 被用来生成解决方案和相关测试用例。对于编码任务,会利用大语言模型生成解决方案及相关测试用例。通过依据测试用例对这些解决方案进行编译和执行,来评估其有效性,进而创建示范数据和偏好数据。这种方法同样适用于评估指令遵循情况。对于每条有约束条件(如长度限制)的指令,会要求大语言模型生成一个 Python 验证函数,以确保生成的回复符合指令要求
数据再利用: 从公共领域收集大量高质量文学作品,并利用 LLMs 来设计不同详细程度的指令。这些指令与原始作品配对,作为示范数据。例如,为了编写具有生动、引人入胜的回应的角色扮演数据,从知识库如维基百科获取详细的角色档案,并指导 LLMs 生成相应的指令和回应。这一过程类似于阅读理解任务,确保了人物简介的完整性
宪法反馈: 为了确保遵守如安全性和价值观等指导原则,编制宪法数据集明确列出需要遵循和避免的原则来指导 LLMs 生成符合或偏离这些指南的响应,作为示范和偏好数据的参考
2.4.2、监督微调(SFT)
整合包含超过 50万 个示例的指令数据集,涵盖了诸如指令遵循、编码、数学、逻辑推理、角色扮演、多语言处理以及安全性等技能领域。模型在序列长度为 32768 个词元的情况下,进行了两个轮次的微调。为优化学习过程,学习率从 $7 \times 10^{-6}$ 逐步降至 $7 \times 10^{-7}$。为应对过拟合问题,采用 0.1 的权重衰减,并将梯度最大值裁剪为 1.0。
2.4.3、基于人类反馈的强化学习(RLHF)
基于人类反馈的强化学习(RLHF)训练机制包含两个连续阶段:离线训练和在线训练。
在离线训练阶段,使用预先编译好的偏好数据集 $P$,通过直接偏好优化(DPO),最大化 $y^{+}_i$ 与 $y^{-}_i$ 之间的似然差异。
在在线训练阶段,模型利用奖励模型实时提供的即时反馈,迭代地实时优化自身性能。具体而言,从当前策略模型中采样多个回复,奖励模型从中选择最受偏好和最不受偏好的回复,形成偏好对,在每个训练周期中用于直接偏好优化。
此外,采用在线合并优化器(Online Merging Optimizer)来缓解对齐成本(alignment tax),即将模型生成与人类偏好对齐所带来的性能下降问题。
3、Qwen 2.5
Qwen 2.5 发布于 2024 年 9 月,预训练数据从之前的 7 万亿扩展到 18 万亿个 token,重点关注知识、编程和数学领域。预训练采用两阶段方法,初始阶段为 4096 个 token,最终阶段扩展到 32768 个 token,并对 Qwen2.5-Turbo 采用逐步扩展策略,达到 262144 个 token。
Qwen 2.5 后训练包括监督微调和多阶段强化学习。其中监督微调使用超过 100 万个样本,涵盖长序列生成、数学问题解决、编码、指令跟随、结构化数据理解、逻辑推理、跨语言迁移和系统指令等方面。强化学习分为离线学习和在线学习两个阶段,离线学习专注于推理、事实性和指令遵循等难以评估的任务,而在线学习则利用奖励模型来提高输出的质量(如真实性、有帮助性、简洁性、相关性、无害性和去偏)。
