GPT(Generative Pre-trained Transformer)是生成式预训练语言模型,基于 Transformer 架构,专注于通过自回归的方式生成自然语言文本,即给定一个输入序列 $x = {x_1, x_2, …, x_t}$,模型学习预测下一个单词 $x_{t+1}$ 的条件概率 $P(x_{t+1} \mid x_1, …, x_t)$。
1、GPT-1
GPT-1 于 2018 年发布,采用了仅有解码器的 Transformer 架构,参数量为 1.17 亿,其通过无监督学习在海量文本数据上预训练,并在特定任务上进行判别式微调来实现自然语言理解任务的显著提升。
1.1、无监督预训练
给定一个无监督的标记语料库 $\mathcal{U}=\lbrace u_{1}, \dots, u_{n} \rbrace$,使用标准的自然语言建模目标来最大化以下似然:
\[L_{1}(\mathcal{U})=\sum_{i}\log P(u_{i}|u_{i-k},\ldots,u_{i-1};\Theta)\]其中 $k$ 是上下文窗口的大小,条件概率 $P$ 使用具有参数 $\Theta$ 的神经网络建模。这些参数使用随机梯度下降法进行训练。
1.2、监督微调
在预训练模型的基础上,使用相应的监督目标对模型进行微调。假设一个标记的数据集 $\mathcal{C}$,其中每个实例包括一系列输入标记 $x^{1},\ldots, x^{m}$,以及标签 $y$。输入通过预训练模型得到最终 Transformer 块的激活 $h_{l}^{m}$,然后将其输入到一个线性输出层,其参数为 $W_{y}$,以预测 $y$:
\[P\left(y\mid x^{1},\ldots, x^{m}\right)=\operatorname{softmax}\left(h_{l}^{m} W_{y}\right).\]其对应的目标函数为:
\[L_{2}(\mathcal{C})=\sum_{(x, y)}\log P\left(y\mid x^{1},\ldots, x^{m}\right).\]为了提高监督模型的泛化能力,并加速收敛,引入语言建模作为辅助目标:
\[L_{3}(\mathcal{C})=L_{2}(\mathcal{C})+\lambda*L_{1}(\mathcal{C})\]1.3、针对特定任务的输入转换
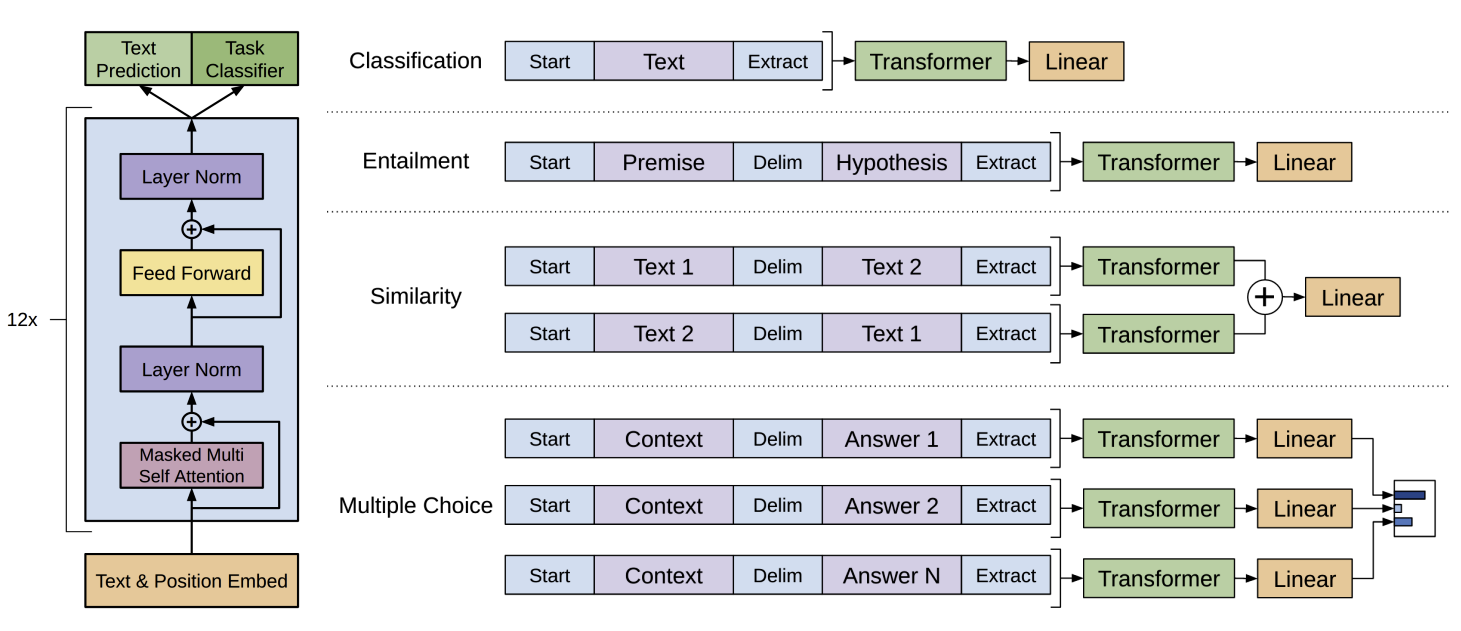
对于某些任务(如文本分类),可以直接进行微调。但对于其他任务(如问答或文本蕴含),需要将结构化输入转换为顺序序列。例如,对于文本蕴含任务,将前提 $p$ 和假设 $h$ 连接起来,中间加上分隔符。
2、GPT-2
GPT-2 发布于 2019 年,继承了 GPT-1 的架构,并将参数规模扩大到 15 亿。GPT-2 尝试通过增加模型参数规模来提升性能,并探索使用无监督预训练的语言模型来解决多种下游任务,而无需显式地使用标注数据进行微调。
2.1、语言建模
语言建模通常被看作是从一组示例 $(x_1, x_2, …, x_n)$ 中进行无监督的概率分布估计,每个示例由可变长度的符号序列 $(s_1, s_2, …, s_n)$ 组成。由于语言具有自然的顺序,通常将符号的条件概率分解为条件概率的乘积:
\[p(x)=\prod_{i=1}^{n}p(s_{n}|s_{1},...,s_{n-1})\]这种方法允许对 $p(x)$ 以及形如 $p(s_{n-k},…,s_{n} \mid s_{1},…,s_{n-k-1})$ 的任何条件概率进行易于处理的采样和估计。
2.2、多任务学习
学习执行单一任务可以表示为在概率框架内估计条件分布 $p(\text{output} \mid \text{input)}$,为了使系统能够执行多个不同的任务,即使对于相同的输入,系统应该不仅依赖于输入,还依赖于要执行的任务。即,系统应建模 $p(\text{output} \mid \text{input},\text{task})$。
2.3、训练数据集
创建名为 WebText 的新数据集,主要通过抓取 Reddit 上的链接来获取文本。为了提高文档质量,要求链接至少获得 3 次点赞,WebText 包含 4500 万个链接的文本子集。为了从 HTML 响应中提取文本,使用 Dragnet 和 Newspaper1 内容提取器的组合进行去重和清理,最终得到包含 800 万篇文档,总计约 40 GB 的文本。
2.4、输入表示
使用字节级编码(BPE)作为输入表示,避免了字符级别和词级别的限制。BPE(Byte Pair Encoding) 是一种基于字符的无监督的分词算法,它通过反复合并最常见的字符对(byte pairs)来构建词汇表,使得模型能够处理词汇中未见的词(OOV,Out-of-Vocabulary)并提高文本表示的效率。
具体的,BPE 会扫描文本,统计所有字节对(相邻的两个字符)的出现频率。接着选取出现频率最高的字节对并将其合并为一个新的子词单元,然后更新词汇表和文本中的所有出现。例如,若 “ab” 是最频繁出现的字节对,它会将 “ab” 视为一个新单元,将文本中的所有 “ab” 替换为这个新单元,并将 “ab” 添加到词汇表中。这个过程会持续迭代,词汇表不断扩大,同时文本表示会变得更紧凑。
3、GPT-3
GPT-3 发布于 2020 年,使用了与 GPT-2 相同的模型架构,但其参数规模扩展到了 1750 亿。GPT-3 引入 “上下文学习(In-context learning)” 概念,允许大语言模型通过少样本学习解决各种任务,消除了对新任务进行微调的需求。
3.1、In-context learning
In-context learning(ICL) 利用模型在预训练阶段获得的大量知识和语言规则,通过设计任务相关的指令和提示模板,引导模型在新的测试数据上生成预测结果。ICL 允许模型在没有显式微调的情况下,通过在输入上下文中提供少量示例来学习新任务。
GPT-3 系统分析了在同一下游任务中,在不同设置下模型学习能力的差异,这些设置可以被视为处于一个反映对任务特定数据依赖程度的范围之中:
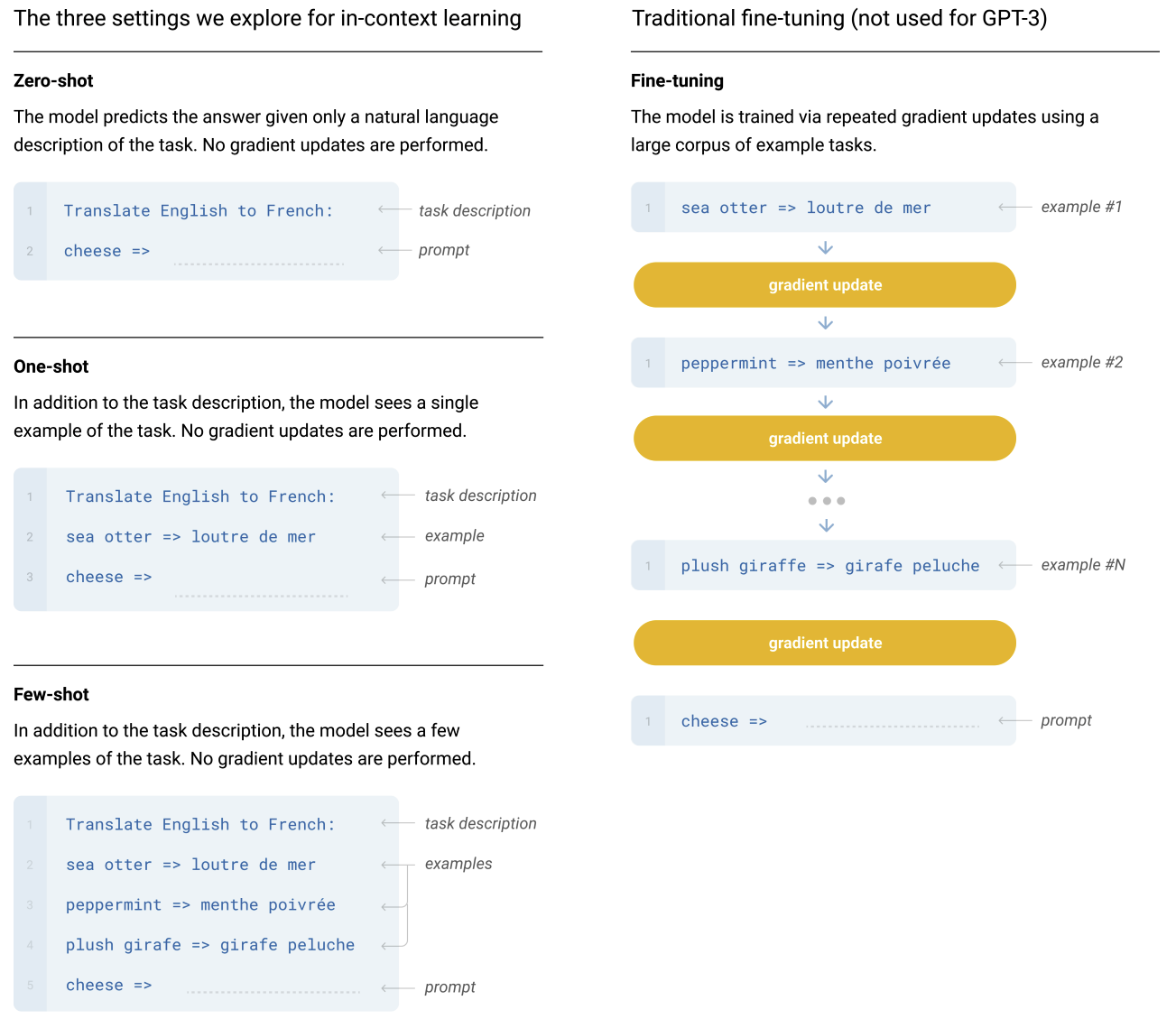
- Fine-Tuning (FT):通过数千到数万个下游任务的监督数据集上更新预训练模型的权重来进行训练。其主要缺点是需要为每个任务创建一个新的大型数据集,可能会在分布外泛化不佳,并且可能会利用训练数据中的虚假特征导致与人类性能的不公平比较。GPT-3 没有采用微调
- Few-Shot (FS):推理时向模型提供任务的几个示例作为条件,但不允许更新权重。少样本学习大大减少了对特定任务数据的需求,并降低了从一个大而狭窄的微调数据集学习到过窄分布的可能性。但这种方法的结果比微调的 SOTA 模型的效果差很多
- One-Shot (1S):单样本与少样本相同,除了任务的自然语言描述外,只允许使用一个示例。将单样本与少样本和零样本区分开来的原因是,它最符合向人类传达某些任务的方式
- Zero-Shot (0S):零样本不允许使用示例,并且仅向模型提供描述任务的自然语言指令
3.2、模型架构
GPT-3 使用与 GPT-2 相同的模型和架构,包括初始化、预归一化和可逆分词,不同之处在于 Transformer 的各层中使用交替的密集和局部带状 稀疏注意力 模式(类似于 Sparse Transformer)。
稀疏注意力机制
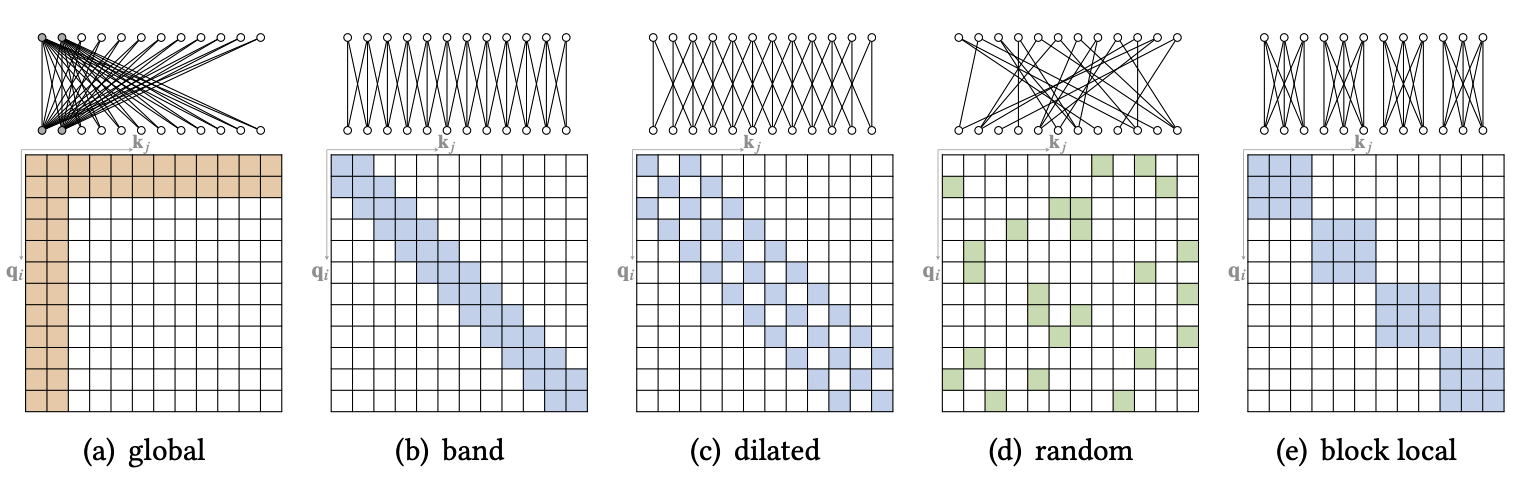
稀疏注意力机制(Sparse Attention Mechanism) 是一种优化 Transformer 模型中计算效率和内存使用的技术。由于标准的自注意力机制需要计算所有词对之间的注意力权重,这导致了随着输入序列长度增加,计算和内存开销呈二次增长 $O(n^2)$ 。稀疏注意力机制通过限制每个单词只能关注一部分其他单词,从而减少了计算复杂度。
- Global Attention:为了缓解稀疏注意力在模拟长距离依赖能力上的退化,可以添加一些全局节点作为节点间信息传播的枢纽
- Band Attention:注意力权重被限制在一个固定的窗口中,每个 Query 只关注其邻居节点
- Dilated Attention:类似于扩张卷积神经网络,通过使用扩张,可以在不增加计算复杂度的情况下增加 Band Attention 的感受野
- Random Attention:为了增强非局部交互的能力,对每个 Query 随机抽取一些边
- Block Local Attention:将输入序列分割成几个不重叠的查询块,每个查询块都与一个局部记忆块相关联,查询块中的所有 Query 只关注相应记忆块中的 Key
4、InstructGPT
InstructGPT 在 GPT-3 的基础上,建立了基于人类反馈的强化学习算法 RLHF,通过代码数据训练和人类偏好对齐进行了改进,旨在提高指令遵循能力,并缓解有害内容的生成。
大型语言模型可能生成不真实、有毒或对用户毫无帮助的输出。InstructGPT 通过强化学习与人类反馈结合的方式,使语言模型在广泛的任务上生成的内容更加符合人类的期望。
InstructGPT 的训练步骤如下:
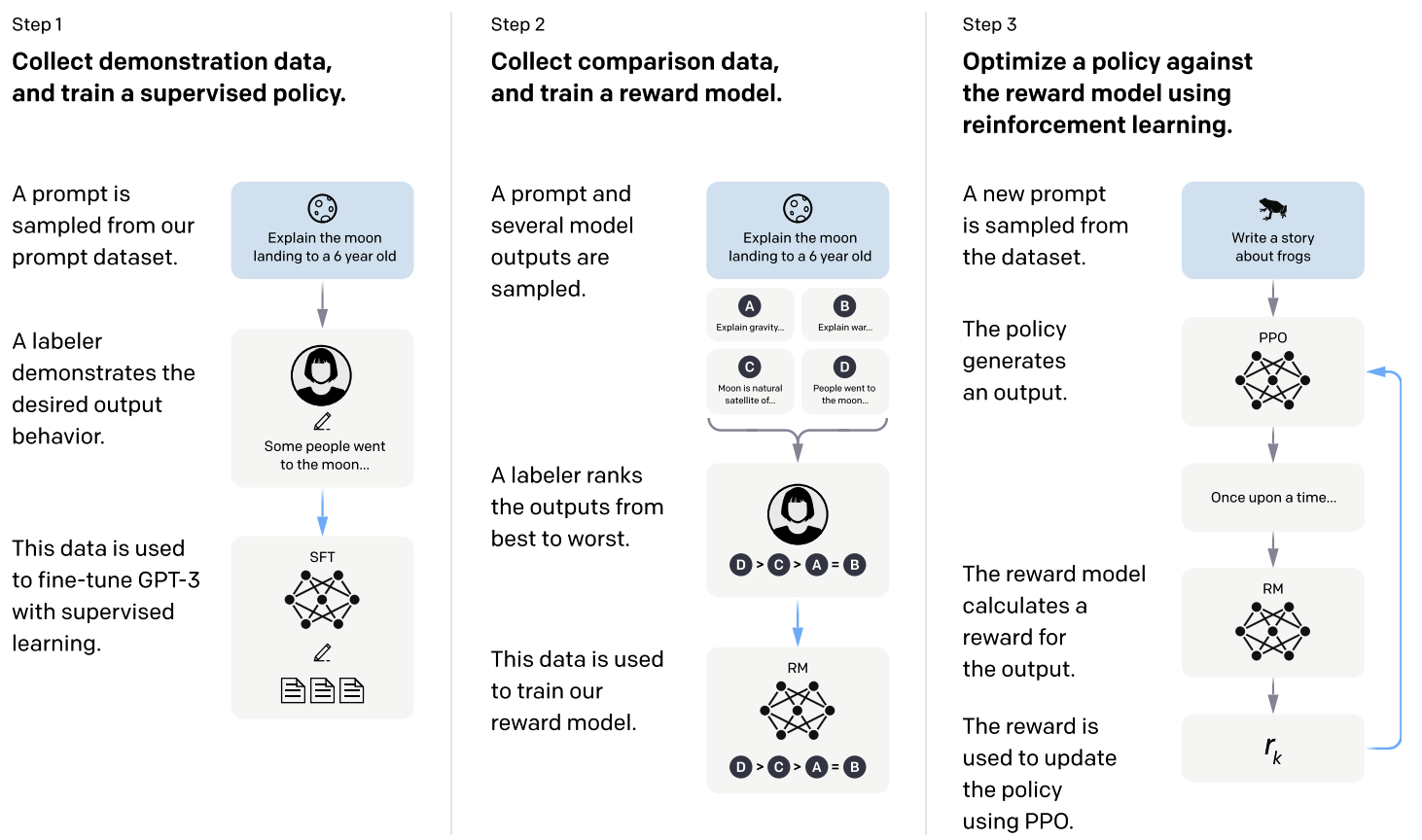
- 数据收集:收集标签器编写的提示和通过 OpenAI API 提交的提示,形成了一个数据集。雇佣 40 名承包商对这些数据进行标注,以生成监督学习的基准数据
- 监督学习微调:使用标签器的标注数据对预训练的 GPT-3 模型进行监督学习微调(SFT),得到 SFT 模型。SFT 模型的训练目标是最小化标签器对模型输出的偏好损失
- 奖励模型训练:收集模型输出之间的比较数据,其中标注员指出他们对于给定输入更倾向于哪个输出。然后训练一个奖励模型(RM)来预测人类偏好的输出。奖励模型的输入是一个提示和一个响应,输出是一个标量奖励
- 强化学习优化:使用近端策略优化(PPO)算法,以奖励模型作为标量奖励,对 SFT 模型进行进一步微调
4.1、数据集
数据集主要由提交给 OpenAI API 的文本提示(prompt)组成,通过检查提示是否有长的公共前缀来启发式地去重,并且限制每个用户 ID 的提示数量为 200。同时根据用户 ID 创建训练、验证和测试分割,以确保验证和测试集不包含训练集中的用户数据。
为了训练最初的 InstructGPT 模型,需要一个初始的指令样式的提示来源来启动这个过程,要求标注者编写三种类型的提示:
- Plain: 简单地要求标注者想出一个任意的任务,同时确保任务的多样性
- Few-shot: 要求标注者想出一个指令,并为该指令提供多个查询/响应对
- User-based: 在 OpenAI API 的候补申请中收到了多个用例,要求标注者根据这些用例提出相应的提示词
基于这些提示(prompt)生成了用于微调过程中的三种不同数据集:
- SFT 数据集: 来自 API 和标注者编写的 13k 个训练提示,包含标注者演示数据,用于训练 SFT 模型
- RM 数据集: 来自 API 和标注者编写的 33k 个训练提示,包含标注者对模型输出的排名,用于训练奖励模型(RM)
- PPO 数据集: 仅来自 API 的 31k 个训练提示,不含任何人类标签,用于强化学习微调(RLHF)
对于每个自然语言提示,任务通常是通过自然语言指令直接指定的(例如,“写一个关于聪明青蛙的故事”),但也可以通过少量示例(例如,给出两个青蛙故事的例子,并提示模型生成一个新的故事)或隐含的延续(例如,提供关于青蛙的故事开头)间接指定。在每种情况下,要求标注者尽力推断写提示者的意图,并要求跳过任务非常不明确的输入。在最终评估中,要求标注员优先考虑真实性和无害性。
4.2、监督微调(SFT)
基于人工标注员编写并提供的示范回答,使用监督学习对 GPT-3 进行微调。模型训练 16 个周期,采用余弦学习率衰减,并设置了 0.2 的残差丢弃率(residual dropout)。根据验证集上的 RM 评分进行最终的 SFT 模型选择。SFT 模型在经过 1 个周期后会在验证损失上出现过拟合;然而,尽管存在过拟合,训练更多周期仍然有助于提高 RM 评分和人类偏好评分。
残差丢弃: 在残差连接的地方,丢弃来自前一层的部分残差信号(不是当前层的激活输出)
4.3、奖励建模(RM)
从移除最后的反嵌入层(unembedding layer:将模型的输出向量映射回词汇表中的一个词汇或子词)的 SFT 模型开始,训练一个模型以接受提示和响应,并输出一个标量奖励。论文中仅使用了 6B 的奖励模型(RM),因为这可以节省大量计算资源,并且发现使用 175B 奖励模型进行训练可能会导致不稳定,因此不太适合作为 RL 过程中值函数(value function)使用。
奖励模型(RM)基于同一输入的两个模型输出之间的对比组成的数据集上进行训练,模型使用交叉熵损失,以对比结果作为标签,其中奖励的差异代表了某个回应相比另一个回应更可能被人类标注员偏好的对数几率。
为了加快比较数据的收集速度,向标注员展示 4 到 9 个响应,并让他们对这些响应进行排序。这为每个提示(prompt)生成了 $\binom{K}{2}$ 个比较,其中 $K$ 是展示给标注员的响应数量。
由于在每个标注任务中的对比之间有很强的相关性,如果简单地将对比打乱到一个数据集中,单次遍历该数据集会导致奖励模型发生过拟合。因此,将每个提示(prompt)的 $\binom{K}{2}$ 个对比作为单个 batch 来训练。这种方法在计算上更高效,因为仅需要为每个生成的回答进行一次前向传播(将多个样本放在一个批次中时,神经网络可以通过一次前向传播同时处理这些样本),而不是对 $K$ 个生成进行 $\binom{K}{2}$ 次前向传递,并且因为避免了过拟合,在验证准确率和对数损失上有了显著的提升。
具体来说,奖励模型的损失函数是:
\[\operatorname{loss}(\theta)=-\frac{1}{\binom{K}{2}} E_{\left(x, y_{w}, y_{l}\right)\sim D}\left[\log\left(\sigma\left(r_{\theta}\left(x, y_{w}\right)-r_{\theta}\left(x, y_{l}\right)\right)\right)\right]\]其中,$r_\theta(x, y)$ 是奖励模型在给定提示 $x$ 和生成内容 $y$ 的情况下,使用参数 $\theta$ 输出的标量值,$y_w$ 是在一对 $y_w$ 和 $y_l$ 中被偏好的生成内容,$D$ 是人类比较数据集。
在训练奖励模型(RM)时,损失函数对奖励值的偏移(即奖励的整体水平)是不敏感的。即,不管奖励的数值范围是多少,只要模型正确地比较不同生成内容的优劣,它的训练效果是不会受到奖励的整体偏移(或常数项)影响的。即在训练过程中,模型不需要特别关心奖励值的具体数值,只要相对顺序正确即可。
因此,通过引入偏置,使得标注数据在经过奖励模型处理后,将奖励分数归一化为均值为 0 的分布,使强化学习算法在学习过程中更好地根据奖励的相对大小和正负来调整行为,避免了因奖励值的绝对大小和初始偏差而导致的学习问题。
4.4、强化学习(RL)
使用 PPO 在给定环境中对 SFT 模型进行微调。该环境是一个 多臂赌博机环境,它会随机提供一个客户提示(customer prompt)并期望模型对该提示给出响应。根据提示和响应,环境会生成一个由奖励模型决定的奖励,并结束这一回合。此外,还在每个 token 上添加了来自 SFT 模型的 每个token的KL惩罚,以缓解奖励模型的过度优化。价值函数 是从奖励模型(RM)初始化的,并将这些模型称为 PPO。
InstructGPT 将 预训练梯度 与 PPO梯度 混合,以解决在公共 NLP 数据集上出现的性能退化问题。InstructGPT 将这些模型称为 PPO-ptx ,并在 RL 训练中最大化以下联合目标函数:
其中,$\pi_{\phi}^{\mathrm{RL}}$ 是学习的 RL 策略,$\pi^{\mathrm{SFT}}$ 是监督训练的模型,$D_{\text{pretrain}}$ 是预训练分布。KL 奖励系数 $\beta$ 和预训练损失系数 $\gamma$ 分别控制 KL 惩罚和预训练梯度的强度。对于 PPO 模型,$\gamma$ 设置为0。
5、GPT-4
GPT-4 发布于 2023 年,首次将输入模态从单一文本扩展到图文多模态。
参考文献
- Improving Language Understanding by Generative Pre-Training
- Language Models are Unsupervised Multitask Learners
- Release Strategies and the Social Impacts of Language Models
- Language Models are Few-Shot Learners
- Generating Long Sequences with Sparse Transformers
- A Survey of Transformers
- Training language models to follow instructions with human feedback
- GPT-4 Technical Report
- Language Models are Unsupervised Multitask Learners
