搜索排序多目标预估和多目标融合
在搜索排序中,用户的行为和目标往往是多样化的,比如点击、收藏、分享、停留时长等。单一的目标优化可能导致整体效果的偏差,因此需要通过多目标预估与多目标融合来更全面地满足用户需求,提升搜索系统的整体效果。
多目标预估可以在模型训练和优化过程中,合理权衡这些不同业务目标之间的关系,避免过度追求某一目标而损害其他目标,使平台在短期收益和长期发展之间找到平衡。
搜索常见的目标包括点击、点赞、收藏、评论、关注、分享、截图等。在多目标建模中,通常采用共享底层网络,多个目标在同一个深度学习模型中共享一部分参数,同时在上层使用独立的任务头进行优化。经过业界的实践,ESSM、ESCM、MMoE、PLE等是应用广泛的模型。
1、多目标预估
1.1、Share Bottom
Share Bottom 是最直接简单的多任务学习(Multi-Task Learning, MTL)模型架构,其基本思想是通过共享底层特征提取层,让不同任务能够共同利用底层特征,从而提升模型的学习能力。
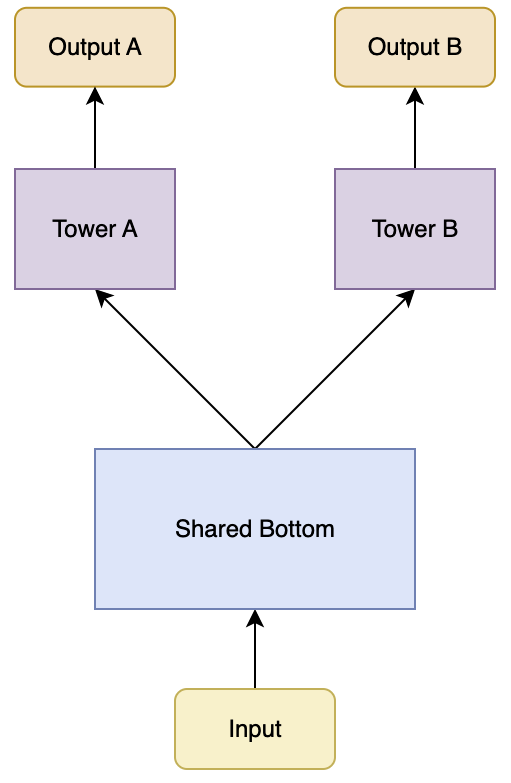
- 负迁移问题
- 当多个任务之间的差异较大,而共享底层网络层过于简单或固定时,可能会出现负迁移现象。即一个任务的学习过程对另一个任务产生负面影响,导致模型在某些任务上的性能下降。模型无法区分不同任务的特定需求,容易导致任务间的冲突
- 任务不平衡问题
- 如果不同任务的数据分布、难易程度或重要性存在较大差异,模型在训练过程中可能会倾向于优化表现较好或数据量较大的任务,导致模型在某些任务的稀疏样本上表现较差,并容易对部分任务过拟合
1.2、MMoE
MMoE(Multi-gate Mixture of Experts) 通过为每个任务构建专属的专家网络,并利用共享网关机制来动态选择不同任务最适合的专家,从而实现有效的任务协同。
任务 $ T_k $ 的最终输出由多个共享专家网络 $(e_1, e_2, \dots, e_N)$ 的加权组合生成,权重由任务特定的门控网络 $g_k$ 动态计算。
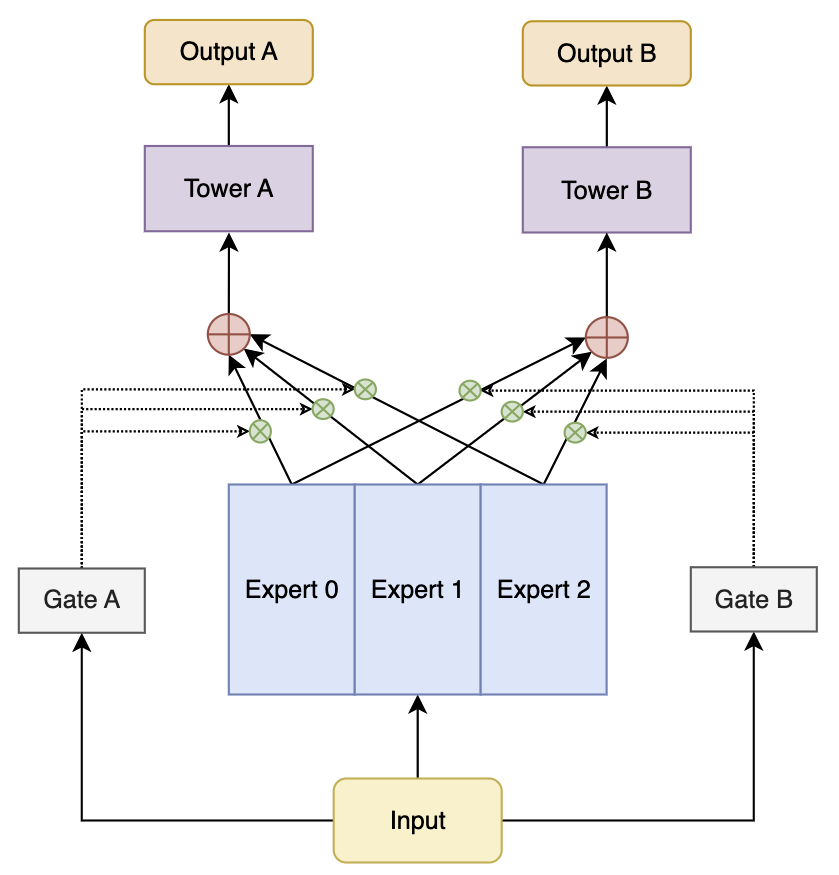
1.2.1、专家网络
每个专家网络的输入为通用特征 $ x $,经过专家网络 $e_i$ 后得到输出 $h_i$:
\[h_i = e_i(x), \quad i = 1, 2, \dots, N\]其中:
- $ e_i $ 是第 $ i $ 个专家网络
- $ h_i \in \mathbb{R}^d $ 是第 $ i $ 个专家网络的输出
1.2.2、门控网络
任务 $ T_k $ 的门控网络根据输入特征 $ x $,计算每个专家的权重 $ g_{k,i} $:
\[g_{k,i} = \text{softmax}\left(W_k \cdot x + b_k\right)_i\]其中:
- $ g_{k,i} \in [0, 1] $ 是专家 $ e_i $ 对任务 $ T_k $ 的权重
- $ W_k $ 和 $ b_k $ 是门控网络的参数
1.2.3、专家输出融合
任务 $ T_k $ 的最终共享特征输出 $ o_k $ 是所有专家输出的加权和:
\[o_k = \sum_{i=1}^N g_{k,i} \cdot h_i\]其中:
- $ g_{k,i} $ 是任务 $ T_k $ 对专家 $ e_i $ 的权重
- $ h_i $ 是专家 $ e_i $ 的输出
1.2.4、任务预测
共享特征 $ o_k $ 传递到任务特定的预测网络 $ f_k $,得到最终的任务预测结果:
\[\hat{y}_k = f_k(o_k)\]其中 $ f_k $ 是任务 $ T_k $ 的特定网络。
1.3、PLE
Progressive Layered Extraction (PLE) 通过引入渐进式分层提取策略,在共享和特定任务之间有效分离参数和信息,解决多任务间的负迁移和跷跷板现象(即不同任务难以同时优化的问题)。
MMoE 核心设计基于共享底层专家(Experts)和动态门控网络(Gate),相比于 MMoE,PLE 增加了:
- 任务独占专家(Task-specific Experts):共享专家网络负责提取任务之间的共享信息,而任务独占专家网络则负责提取任务特定的信息
- 多层渐进提取机制:包含多个层级的专家网络和门控网络,每个层级的专家网络专注于学习不同层次的特征表示。在底层,专家网络学习较为通用的特征,随着层级的上升,专家网络逐渐学习到更任务特定的特征
PLE 通过上述设计有效缓解了如下问题:
- 负迁移(negative transfer): 当任务之间相关性较弱时,共享参数反而导致模型性能下降,PLE 通过任务间共享模块和任务特定模块的有效分离,减少任务间冲突
- 跷跷板现象(seesaw phenomenon): 指一个任务的性能提升往往以牺牲另一个任务的性能为代价,PLE 多层提取机制逐步增强不同任务的表现,同时保持整体性能稳定
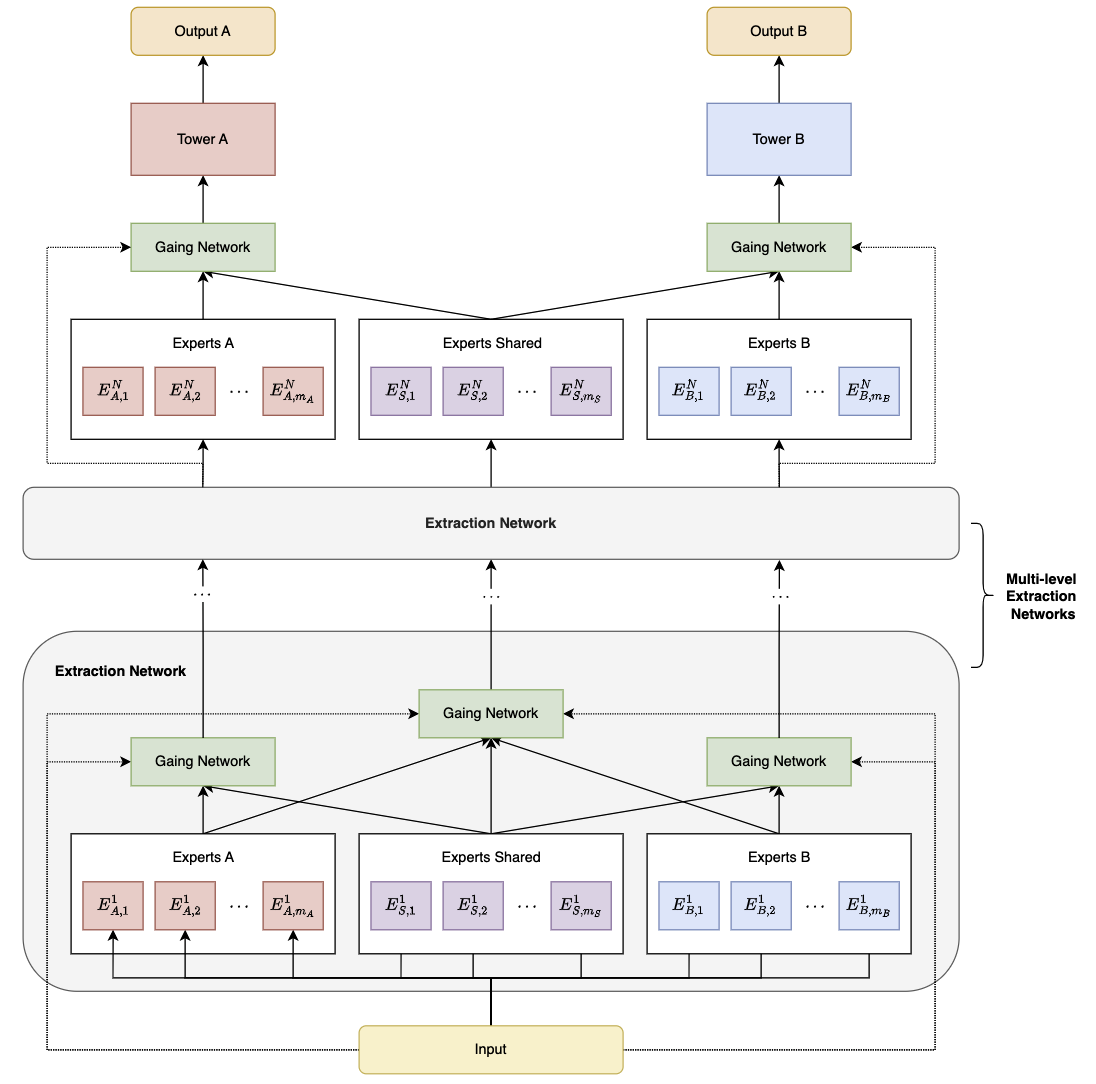
如图,Experts A 和 Experts B 为任务 A 和任务 B 的独占专家系统,Experts Shared 为共享专家系统,Gating Network 为门控网络,每个任务采用独占专家和共享专家中的多个 Expert。
任务 $k$ 的门控网络输出公式为:
\[g^{k}\left(x\right)=w^{k}\left(x\right)S^{k}\left(x\right)\]其中,$x$ 为输入表示,$w^{k}$ 为加权函数以表示专家系统 $S^{k}$ 中 Experts 的权重:
\[w^{k}(x)=\operatorname{Softmax}(W_{g}^{k}x)\]其中,$W_{g}^{k}\in R^{(m_{k}+m_{s})\times d}$ 为参数矩阵,$m_{s}$ 和 $m_{k}$ 分别是共享专家和任务 $k$ 的特定专家的数量,$d$ 是输入表示的维度。$S^{k}$ 由共享专家和任务 $k$ 的独占专家组成:
\[S^{k}(x)=[E_{(k,1)}^{T},E_{(k,2)}^{T},\cdots,E_{(k,m_{k})}^{T},E_{(s,1)}^{T},E_{(s,2)}^{T},\cdots,E_{(s,m_{s})}^{T}]^{T}\]即,任务 $k$ 的预测输出为:
\[y^{k}(x)=t^{k}(g^{k}(x))\]其中 $t_{k}$ 表示任务 $k$ 的塔网络(tower network),$g_{k}$ 如上所述为任务 $k$ 的门控网络(gating network)。
2、多目标融合
多目标预估会对每个目标预测一个分数,在文档排序时需要综合多个目标打分,即采用多目标融合将多个优化目标(点击率、转化率、相关性、停留时长、点赞率、收藏率、分享率、评论率、关注率、质量分等)综合在单一评分框架中,从而实现对文档的统一排序,平衡用户体验和业务指标。
2.1、融合公式
2.1.1、加法融合
加法融合是最简单的一种方式,将各目标的分数按权重线性加权求和,生成最终分数,适合目标分数量级一致的情况。
设有 $ n $ 个目标,每个目标的得分为 $ S_i $,对应的权重为 $ w_i $(满足 $ \sum_{i=1}^n w_i = 1 $),则最终得分 $ S_{\text{final}} $ 定义为:
\[S_{\text{final}} = \sum_{i=1}^n w_i S_i\]2.1.2、乘法融合
乘法融合通过乘积的方式将各目标得分结合,通常用于强调目标之间的相互增强效果,适合目标之间具有非线性放大或削弱关系的情况。
\[S_{\text{final}} = \prod_{i=1}^n S_i^{w_i}\]等价于加权几何平均:
\[S_{\text{final}} = \exp\left(\frac{1}{\sum_{i=1}^n w_i} \sum_{i=1}^n w_i \ln S_i \right)\]2.1.3、带权指数融合
带权指数融合通过对目标分数进行指数放大后加权,增强高分目标的影响力,适合目标分数分布差异较大、需要增强高分贡献的场景。
\[S_{\text{final}} = \sum_{i=1}^T (\alpha_i + w_i S_i)^{\beta_i}\]其中,$\alpha_i$ 为目标偏置,$\beta_i$ 是调整目标权重的指数参数,用于非线性处理。
2.1.4、基于排名的融合
当目标分布不稳定时,基于排名的融合方法通过对每个目标的得分排序,按排名进行融合,只关注文档在各目标中的相对顺序,避免目标分数尺度不一致的影响。
设目标 $ i $ 的分数对应排名为 $ R_i $,则最终得分定义为:
\[S_{\text{final}} = \sum_{i=1}^n w_i \cdot f(R_i)\]其中:
- $ R_i $ 是目标 $ i $ 的排名(如第 $ R_i $ 名得分)。
- $ f(\cdot) $ 是排名到分数的映射函数,如 $ f(R) = 1/R $ 或 $ f(R) = e^{-R} $。
- $ w_i $ 是权重。
另一种实现是基于排名的加权投票:
\[S_{\text{final}} = \sum_{i=1}^n w_i \cdot \mathbb{I}(R_i \leq k)\]其中 $ \mathbb{I} $ 是指示函数,表示目标 $ i $ 的排名是否在前 $ k $ 名。
2.2、目标分预处理
在排序融合公式中,预处理目标分的步骤是关键环节,特别是在目标分分布不均或不稳定时,通过特定的变换处理,可以显著提高排序性能。
2.2.1、Min-Max 归一化
归一化用于将目标分映射到指定的范围(通常是 [0,1] 或 [-1,1]),以消除不同目标分之间的量纲差异,确保它们在同一尺度上,便对不同尺度的目标分进行统一处理:
\[x' = \frac{x - \min(x)}{\max(x) - \min(x)}\]- 扩展到任意范围 $[a, b]$: \(x' = a + \frac{(x - \min(x)) \cdot (b - a)}{\max(x) - \min(x)}\)
2.3、搜参算法
在排序融合公式中,融合公式的权重参数对最终排序效果有着至关重要的影响。人工设定权重虽然直观,但往往依赖于经验,难以在复杂场景中找到全局最优解。因此,搜参算法成为一种重要的优化工具,通过自动化手段在参数空间中搜索最优参数组合,以最大化排序效果或业务指标。
2.3.1、贝叶斯优化
贝叶斯优化(Bayesian Optimization)是一种基于贝叶斯统计方法的全局优化算法,适用于黑盒函数优化问题。贝叶斯调参能够利用历史的评估结果,通过构建目标函数的概率模型,选取具有最大潜在收益的参数点进行评估,从而以较少的迭代次数找到最优参数。具体步骤如下:
-
定义目标函数:定义目标函数 $f(x)$ ($x$ 是超参数)用于评估召回合并策略的效果
\[f(\mathbf{w})=\mathbf{Metric}(\mathbf{Merge}(\mathrm{Recalls}(\mathbf{w})))\]- $\text{Recalls}(\mathbf{w}) = [R_1(w_1), R_2(w_2), \dots, R_n(w_n)]$ 表示来自不同通道的召回结果,每个 $R_i(w_i)$ 是通道 $i$ 根据权重 $w_i$ 所返回的候选集
- $\text{Merge}(\cdot)$ 表示将各个通道的召回结果按权重加权融合
- $\text{Metric}(\cdot)$ 是根据合并后的候选集评估的性能指标
-
设置参数空间:如果使用加权平均的合并方式,可以将每个通道的权重作为调节参数进行优化
- 比如,设定权重参数 $\mathbf{w}=[w_{1},w_{2},\cdot\cdot\cdot,w_{n}]$,每个召回通道的权重 $w_{i}$ 影响候选项排名和选择
-
初始化高斯过程:为待优化的参数空间设定先验分布,通常使用高斯过程(Gaussian Process, GP)作为先验,表示对参数空间的初步认识
\[p(f(\mathbf{w}))\sim{\mathcal{G P}}(m(\mathbf{w}),k(\mathbf{w},\mathbf{w}^{\prime}))\]- 其中 $m(\mathbf{w})$ 是目标函数的均值函数,通常假设为零;$ k(\mathbf{w}, \mathbf{w}’) $ 是协方差函数,用于表示不同参数配置之间的相似性
-
更新后验分布:在每次迭代中,根据当前的参数空间和目标函数值,更新高斯过程的后验分布,并基于当前的后验分布生成新的参数选择。贝叶斯调参使用获取函数(Acquisition Function)来选择下一个要评估的参数点。常见的获取函数如期望改进(Expected Improvement, EI)
\[\alpha(\mathbf{w}) = \mathbb{E}[ \Delta f(\mathbf{w}) ] = \mathbb{E}[ \max(0, f(\mathbf{w}_{\text{best}}) - f(\mathbf{w})) ]\]- $f(\mathbf{w}_{\text{best}})$ 是当前最好的目标函数值
- $\Delta f(\mathbf{w})$ 是期望的改进
-
选择下一个评估点:通过最大化获取函数来决定下一个评估点。获取函数根据当前的后验分布选择一个最有可能提升目标函数值的参数组合,从而进行下一轮评估
\[\mathbf{w}^*=\arg \max _{\mathbf{w}} \alpha(\mathbf{w})\] -
重复迭代:贝叶斯优化会根据每一轮评估的结果,调整先验分布,不断优化目标函数,最终找到全局最优的参数配置
\[p(f(\mathbf{w})\mid\mathbf{w}^{*},f(\mathbf{w}^{*}))\sim{\mathcal{G}}{\mathcal{P}}({\mu}(\mathbf{w}),\Sigma(\mathbf{w}))\]
最终,贝叶斯优化会返回最优的参数 $\mathbf{w}^*$。
2.4、模型融合
除了基于人工设定权重参数或搜参算法的融合公式,可以利用数据驱动的方式,自动学习权重参数,甚至跳出线性公式,直接学习最终排序分数。
2.4.1、LTR建模
采用学习排序(Learning to Rank, LTR)建模融合分的方式,是通过模型将多目标预估分数结合用户、查询、文档特征转化为最终排序分数的过程。
LTR 的目标是优化一个排序函数 $ f $,使得对于一个查询 $ q $,能对候选文档列表 $ D $ 排出最佳顺序。
- 输入:查询 $ q $、文档特征 $ x_i $ 和初始目标预估分数 $ s_i $。
- 输出:排序得分 $ y_i = f(x_i, s_i) $。
不同 LTR 方法定义的损失函数不同,具体可分为 Pointwise、Pairwise、Listwise。
Pointwise Loss
Pointwise Loss 只关注单个候选项(如分类或回归任务)。
-
均方差(Mean-Square Error,MSE)
- 定义:将排序问题视为预测相关性分数 $ \hat{y}_i $,并与真实相关性标签 $ y_i $ 之间最小化误差。
- $ y_i $:第 $ i $ 个样本的真实标签(评分)
- $ \hat{y}_i $:模型预测分数
-
交叉熵(Cross Entropy,CE)
- 定义:将LTR的最终目标定义为 分类 任务,输出结果为某个互动行为的概率。分类任务采用交叉熵损失,交叉熵主要用于衡量两个概率分布之间的差异:
- $y_{i}$ 是真实标签的独热编码向量,第 $i$ 类的标签为 1,其它类别为 0
-
- $\hat{y}_{i}$ 是模型对于第 $i$ 类的预测概率
Pairwise Loss
Pairwise Loss 关注候选项之间的两两比较。
-
对比损失
- 定义:对比损失衡量两个文档的相对排序是否正确。如果文档对的相关性排序是正确的,那么损失应该较小;如果排序不正确,则损失应该较大:
- $ y $ 是文档对的标签,取值为 0 或 1,表示文档 $ D_1$ 是否应该排在文档 $ D_2$ 之前
- $ d $ 是文档 $ D_1$ 和 $ D_2$ 在模型预测中的距离(通常是两者的评分差)
- $ m $ 是一个超参数,表示 “margin”(边际),即在没有损失的情况下,文档的评分差需要达到的最小值
-
RankNet损失
- 定义:RankNet 使用 对数损失 来训练排序模型。RankNet 通过概率的形式预测文档的相对排序,给定一对文档 $ D_1$ 和 $ D_2$ ,模型输出一个概率,表示 $ D_1$ 比 $ D_2$ 相关的概率:
- $ p_{ij}$ 是文档对 $ D_1$ 和 $ D_2$ 的真实排序标签(如果 $ D_1$ 应该排在 $ D_2$ 前面,则 $ p_{ij} = 1$ ,否则为 0)
- $ \hat{p}_{ij}$ 是模型预测 $ D_1$ 排在 $ D_2$ 前面的概率
Listwise Loss
Listwise Loss 直接优化一个完整候选列表的排名质量。
- LambdaRank
- 定义:LambdaRank 在 RankNet 的基础上进一步发展,旨在直接优化排序指标(如 NDCG)而设计。
-
目标函数: LambdaRank 的核心在于设计与排名指标相关的动态梯度权重,以高效优化目标。
-
NDCG 指标
\[\text{NDCG@k} = \frac{\sum_{i=1}^k \frac{2^{y_i} - 1}{\log_2(i + 1)}}{\text{IDCG@k}}\]- $ y_i $:文档 $ i $ 的相关性标签(通常是人工标注或规则确定的相关性得分)
- $ i $:文档在当前排序中的位置
- $ \text{IDCG@k} $:理想情况下的 DCG 值(Ideal DCG)
-
梯度
- 定义:对于候选文档对 $ (i, j) $,假设 $ y_i > y_j $(即文档 $ i $ 比 $ j $ 更相关),对应的梯度更新为:
- $ \Delta Z_{ij} $:交换文档 $ i $ 和 $ j $ 后,排名指标(如 NDCG)的增量变化 \(\Delta Z_{ij} = \left| \frac{1}{\log_2(1 + \text{rank}_i)} - \frac{1}{\log_2(1 + \text{rank}_j)} \right| \cdot \left| 2^{y_i} - 2^{y_j} \right|\)
- $ \sigma(s_j - s_i) $:模型预测的分数差对应的 Sigmoid 函数 \(\sigma(s_j - s_i) = \frac{1}{1 + \exp(s_i - s_j)}\)
-
-
损失函数:LambdaRank 的损失函数是基于梯度权重的更新,而不是显式地定义为一个封闭公式。但可以通过梯度描述模型的优化方向:
\[\mathcal{L}_{\text{LambdaRank}} = \sum_{i,j} \lambda_{ij} \cdot \log(\sigma(s_i - s_j))\] -
梯度更新:对文档 $ i $ 的得分 $ s_i $ 的梯度更新规则为:
\[\frac{\partial \mathcal{L}}{\partial s_i} = \sum_{j \neq i} (\lambda_{ij} - \lambda_{ji})\]- 如果 $ y_i > y_j $,则 $ \lambda_{ij} > 0 $,模型需要提升 $ s_i $
- 如果 $ y_i < y_j $,则 $ \lambda_{ij} < 0 $,模型需要降低 $ s_i $
总结
搜索业务往往需要同时满足多个不同的优化目标,例如点击率、转化率、用户停留时长等单一指标难以全面衡量搜索效果。这些目标之间既存在关联性,又可能存在冲突,单独优化某一个目标可能导致其他目标的效果下降。
因此,多目标预估的目标是全面建模不同目标的特征和关系,实现更精准的目标预估,从而为后续的多目标融合提供高质量的输入。此外,多目标预估还能避免单一目标带来的局限性,提高排序模型在不同业务场景下的鲁棒性和泛化性,确保搜索结果能够在多维度上平衡用户体验与商业价值,最终实现搜索系统整体效果的最大化。
多目标预估通过多任务学习(如MMoE、PLE)或独立建模,对各目标进行精准建模和预测;多目标融合则通过线性加权、搜参算法或学习排序(LTR)等方式,将多个目标的预估结果进行整合,得到最终排序分数。在实际应用中,多目标预估和融合面临以下难点:
- 目标冲突
- 难点:不同目标之间可能存在天然的冲突,比如优化点击率(CTR)可能导致转化率(CVR)下降,或者提高短期收益可能影响长期用户留存
- 方案:
- 多任务学习框架:使用MMoE、PLE等模型共享底层特征,建模不同目标之间的关系,平衡目标之间的权衡
- Pareto 最优:引入多目标优化中的Pareto最优解,寻找各目标的最优平衡点
- 引入权重调整机制:在不同场景下灵活调整各目标的权重比例
- 数据稀疏与目标样本不均衡
- 难点:不同目标的样本数据分布可能存在显著差异,例如点击行为数据较多,而转化或购买行为数据较少,导致模型训练不均衡
- 方案:
- 加权损失函数:对稀疏目标增加权重,确保在训练中得到足够的关注
- 数据增强:对稀缺目标样本进行数据增强,提升模型对小样本目标的学习效果
- 方案:
- 难点:不同目标的样本数据分布可能存在显著差异,例如点击行为数据较多,而转化或购买行为数据较少,导致模型训练不均衡
- 目标评估与效果验证
- 难点:多目标的最终效果很难通过单一指标进行衡量,不同目标的贡献也很难拆分清晰
- 方案:
- 离线指标评估:使用NDCG、MAP等评价指标进行综合评估
- 人群分层分析:拆分不同用户人群(高活、低活用户),针对不同群体分别进行效果分析
- 业务目标一致性
- 难点:目标预估和融合可能与业务的长期战略目标存在偏差,导致局部指标优化却未带来整体收益
- 方案:
- 全链路一致性:确保预估阶段、融合阶段与整体业务目标保持一致
- 目标动态调整:根据业务发展阶段,动态调整不同目标的优先级和权重
- 长期效果监控:引入长期ROI等指标,监控多目标策略的长期效果
