1、相关性
搜索相关性是搜索引擎的核心,它决定了用户查询Query和系统返回结果Doc之间的匹配度。这种匹配度的高低,对于搜索用户体验有着至关重要的影响。
2、相关性标准
做好相关性需要一个标准分档体系用来评估和度量 查询Query 与 文档Doc 之间匹配程度。相关性标准的制定可以帮助搜索系统量化相关性,从而在排序和优化过程中提供依据。不同的搜索产品可能有不同的相关性标准和分档方式,但一般都会基于某些通用的标准化方法。
工业界普遍采用分级标准来衡量查询与文档的相关性。常见的相关性等级有以下几种:
- 0:完全不相关(Not Relevant)
- 定义:文档与查询没有任何关联
- 说明:完全无法满足用户的主需或次需。文档内容与用户查询毫无关联,对需求没有任何帮助
- 示例:
- 查询:“iPhone 15 Pro Max 价格” 完全不相关文档:讲述 Android 系统发展历程,或完全无关的其他内容
- 1:略微相关(Marginally Relevant)
- 定义:文档与查询在某些方面有关,但对用户问题的解答效果很差,有一定参考价值
- 说明:对用户需求几乎没有帮助。用户主需和次需几乎没有覆盖,仅包含与查询主题或意图相关的少量无关紧要的信息。文档主题与查询存在部分语义或背景的弱相关性,但不直接匹配
- 示例:
- 查询:“iPhone 15 Pro Max 价格” 略微相关文档:讨论 iPhone 的历史发展或者旧款 iPhone 的价格信息,与当前查询需求相关性较弱
- 2:部分相关(Partially Relevant)
- 定义:文档与查询有一定的相关性,可以部分回答用户的问题或满足查询需求
- 说明:文档可能涉及与查询相似或相关的主题,但无法直接满足查询的核心需求。即部分满足用户主需,但信息不全面、不精确或次需偏离
- 示例:
- 查询:“iPhone 15 Pro Max 价格” 部分相关文档:讨论 iPhone 15 系列的发布信息,但没有列出价格,或者文档内容中只有一句提到价格信息
- 3:高度相关(Highly Relevant)
- 定义:文档与查询紧密相关,可以完全满足用户查询的需求
- 说明:查询的主需求得到清晰且全面的回答,但附加需求(如果有)可能没有涵盖,或者覆盖得较为浅显。文档主题与查询一致,内容表达与用户预期匹配,但可能有次要信息干扰或表达上不够紧凑。即文档的部分次级信息可能稍微偏离查询主题,但总体与查询主旨一致
- 示例:
- 查询:“iPhone 15 Pro Max 价格” 高度相关文档:列出 iPhone 15 的价格,但没有明确区分 Pro Max 版本,或仅涉及部分价格信息
- 4:完全相关(Perfectly Relevant)
- 定义:文档与查询完全匹配,解决了查询提出的所有问题,符合用户期望
- 说明:查询背后的主需求被文档内容精准覆盖,提供了明确且详尽的答案。对于存在次需的场景,文档的主信息部分集中覆盖主需,次需部分如果涉及则为附加但不是关键点。文档主题与查询主题高度一致,语义、表达方式和查询意图对齐
- 示例:
- 查询:“iPhone 15 Pro Max 价格” 完全相关文档:详细列出 iPhone 15 Pro Max 各个版本的价格,清晰明确
如上,文档主体内容是否满足用户主需始终是评估相关性的首要标准,次需是考虑文档优劣的附加因素。若查询语义不明确,以主流用户群体的主要需求为评估标准,结合实际业务目标判断。
3、相关性技术
搜索相关性技术通过计算 查询Query 和 文档Doc 的相关程度来判断 Doc 是否满足用户 查询Query 的需求。目前主流的相关性技术是采用预训练语义模型的(BERT),除此之外,传统的文本匹配和 GBDT 模型依然可以在较少算力的支持下提供有效信息。
3.1、文本匹配
传统的搜索相关性技术依赖于词频、词项匹配等方法,这些方法简单高效,适用于早期的信息检索系统。
常见的相似度匹配算法有 TF-IDF 和 BM25,其基本思想是,Query 中的词在 Doc 中出现次数越多,则 Query 和 Doc 越相关。
3.1.1、TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)用于衡量一个词在文档中的重要性,其结合了词在文档中的频率(TF)和词在整个语料库中的稀有性(IDF)来作为判断依据。
TF-IDF的计算公式为:
\[\text{TF-IDF}(t, d, D) = \text{TF}(t, d) \times \text{IDF}(t, D)\]其中,$ t $为目标词项(term),$d$为目标文档,$D$为语料库(包含所有文档)。
-
词频(TF)
\[\text{TF}(t, d) = \frac{f(t, d)}{\sum_{t' \in d} f(t', d)}\]- $f(t, d)$:词 $t$ 在文档 $d$ 中出现的次数
- $\sum_{t’ \in d} f(t’, d)$:文档 $d$ 中所有词出现的总次数
- TF 是一个局部指标,表示一个词在当前文档中的重要性。词在文档中出现得越多,其重要性可能越高
-
逆文档频率(IDF)
\[\text{IDF}(t, D) = \log \frac{|D|}{1 + |\{d \in D : t \in d\}|}\]- $|D |$:语料库中文档的总数
- $|d \in D : t \in d |$:包含词 $t$ 的文档数量(文档频率)
- IDF 是一个全局指标,表示词在整个语料库中的稀有性。词在整个语料库中出现得越少,其区分性越强
通过将 TF 和 IDF 相乘,TF-IDF 能有效提升那些对当前文档具有区分性的关键词的权重,降低全局常见但区分性较弱词的权重。
3.1.2、BM25
BM25 对 TF-IDF 进行了改进,BM25的计算公式为:
\[{\mathrm{BM25}}(t,d,D)={\mathrm{IDF}}_{\mathrm{BM25}}(t,D)\times{\mathrm{TF}}_{\mathrm{BM25}}(t,d,D)\]其中,$ t $为目标词项(term),$d$为目标文档,$D$为语料库(包含所有文档)。
-
词频(TF修正)
\[\mathrm{TF}_{\mathrm{BM25}}(t,d,D)=\frac{f(t,d)\cdot(k_{1}+1)}{f(t,d)+k_{1}\cdot\left(1-b+b\cdot\frac{|d|}{\mathrm{avgdl}}\right)}\]- $f(t, d) $:词 $ t $ 在文档 $ d $ 中的词频(Term Frequency)
- $|d | $:文档 $ d $ 的长度(即词的总数)
- $ \text{avgdl} $:语料库中文档的平均长度
- $ k_1 $:调节词频饱和程度的参数,通常取值范围为 [1.2, 2]
- $ b $:调节文档长度归一化的参数,通常取值范围为 [0, 1]
- 词频饱和:对 $f(t,d)$ 引入非线性加权,防止高词频对得分过度影响
- 文档长度归一化:引入参数 $b$ 平衡长文档和短文档
-
逆文档频率(IDF修正)
\[\mathrm{IDF}_{\mathrm{BM25}}(t,D)=\log\frac{N-n(t,D)+0.5}{n(t,D)+0.5}\]- $N$:语料库 $D$ 中的文档总数
- $n(t,D)$:包含词 $t$ 的文档数
- 增加了平滑项,避免在极端情况下分母为 0,同时使常见词的权重更低
BM25 的改进体现在对 TF 进行非线性调节(饱和处理)和引入文档长度归一化,同时对 IDF 进行了平滑处理,解决了 TF-IDF 中的高词频偏差和长文档劣势问题。
3.2、GBDT 模型
采用 GBDT(Gradient Boosting Decision Tree) 模型进行相关性分档是一种常见的技术方案。GBDT 作为一种强大的集成学习方法,能够有效地从多维特征中学习到非线性关系。
3.2.1、GBDT 算法
GBDT(Gradient Boosting Decision Tree) 是一种基于梯度提升(Gradient Boosting)框架的集成学习方法,通过将多个弱分类器(通常是决策树)结合起来,逐步优化模型的预测结果。
GBDT 是一种 加法模型,每个新加入的决策树(基学习器)通过拟合前一轮模型的残差来修正预测结果。给定一个损失函数和模型的当前预测值,目标是通过训练下一棵树来减少损失函数的值。每棵树在每次迭代中都要拟合 负梯度,即残差的负方向:
\[F(x) = F^{(0)} + \sum_{t=1}^{T} \gamma_t h_t(x)\]其中:$ F^{(0)}$ 是初始模型,$ \gamma_t $ 是每棵树的学习率(缩放因子),用于控制每棵树对最终模型的贡献大小,$ h_t(x)$ 是第 $t$ 轮训练得到的决策树,$ T $ 是树的总数。在每一轮中,新的树 $h_t(x)$ 会学习上一轮预测的残差,学习的过程是基于梯度下降优化目标函数。
3.2.2、GBDT 相关性特征
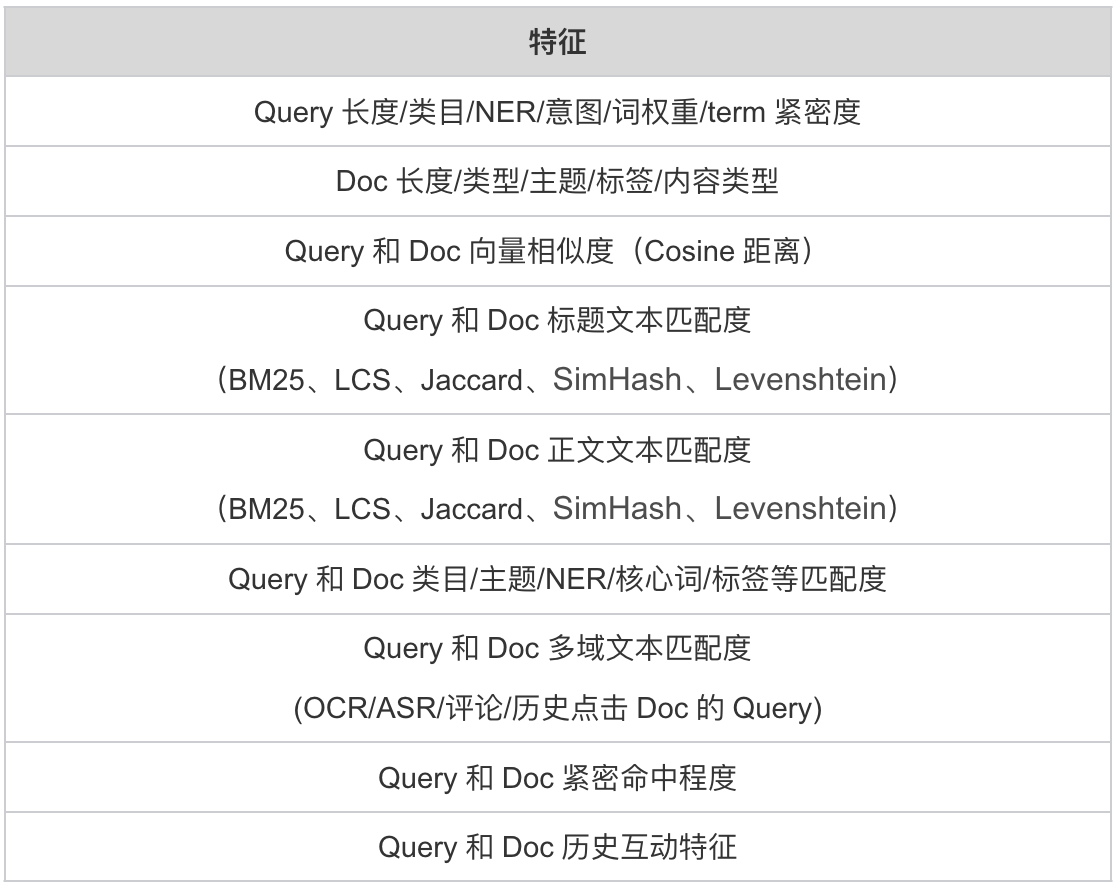
GBDT以相关性档位为学习目标,输入特征可分为:
- 查询特征:包括查询的关键词、查询意图等信息
- 文本特征:查询的长度、词汇分布、查询类型(精确匹配、模糊匹配等)
- 行为特征:用户历史查询、点击模式等
- 文档特征:包括文档的标题、正文内容、发布时间等信息
- 文本特征:文档的长度、主题、内容类型
- 内容质量:文档的完整性、关键词覆盖情况、SEO优化情况
- Query-Doc 特征:描述查询与文档之间的匹配程度的特征
- 匹配度:关键词匹配、词向量相似度等
- 查询与文档的交互特征:历史互动行为(点击、评论、分享等)
常用的特征如下:
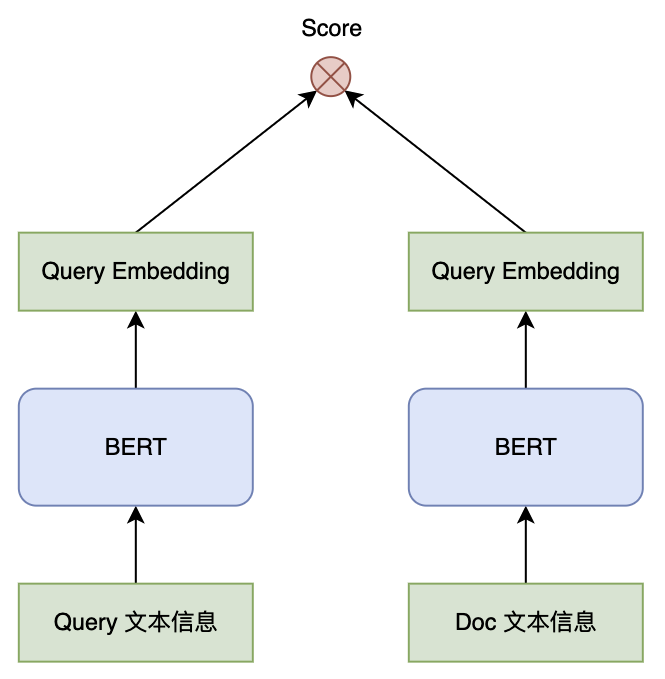
3.3、BERT 双塔模型
作为搜索排序重要信号,相关性计算贯穿粗排和精排。由于粗排需要计算的候选 Doc 较多,考虑到性能压力,BERT 双塔模型通常被选择用在粗排阶段的相关性计算中。
BERT 的双塔模型分为 Query塔 和 Doc 塔,其中 Query塔 的输入通常是 Query文本 加上 Query 的 NER、类目等文本特征,Doc塔 的输入一般为文档标题、正文内容、关键字、主题、摘要等文本特征,若文档内容过长,则需要做截断处理或者提取文档摘要作为输入。
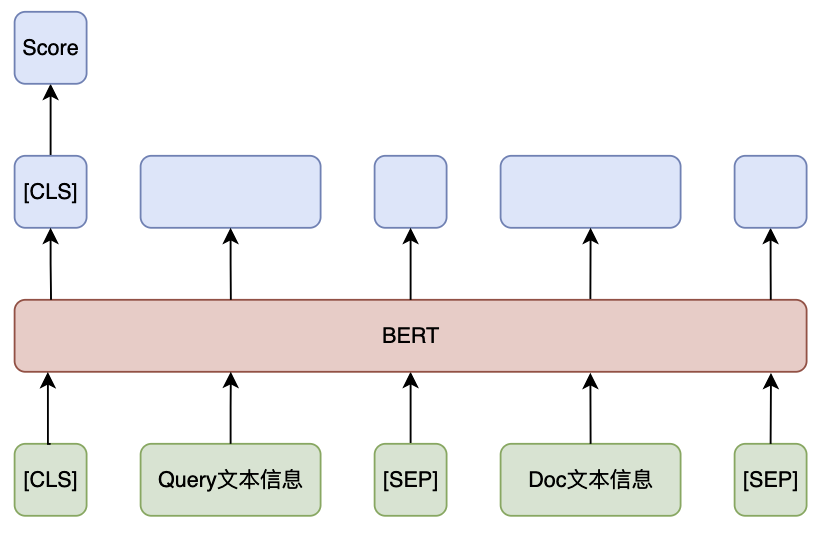
3.4、BERT 单塔模型
基于交互计算的 BERT单塔 模型能够直接捕捉 Query 和 Doc 之间的细粒度交互信息,由于计算量较大,普遍应用于精排阶段的相关性计算中。
业内通过在模型中引入显示匹配矩阵建模字词的匹配关系,并结合BERT深度语义信息,可以有效带来效果提升。匹配矩阵内元素通过 0 或 1 描述 Query 中的 Term 和 Doc 中的 Token 是否相同:
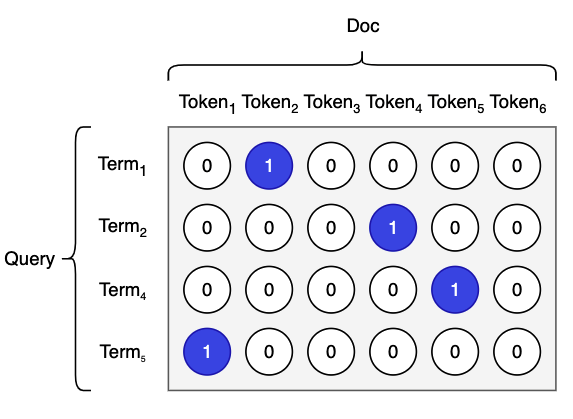
字词匹配矩阵通过和BERT输出的 Query 和 Doc 向量融合后再做相关性打分计算。
3.5、模型训练
3.5.1、多阶段训练
BERT 相关性模型通常需要多阶段的训练,在训练中通过海量的搜索互动数据和人工标注数据,逐步优化模型对 Query 和 Doc 之间语义匹配的理解能力。
- 通用预训练
- 数据:大规模通用语料
- 任务:
- MLM:全词掩码,短语掩码,实体掩码,动态掩码,Span-Level 掩码等
- NSP/SOP:预测下一句,预测排序
- 领域预训练
- 数据:海量搜索点击数据
- 任务:
- MLM:全词掩码,短语掩码,实体掩码,动态掩码,Span-Level 掩码等
- 点击预测:判断 Query 和 Doc 是否发生搜索点击行为
- 领域微调
- 数据:海量搜索点击数据
- 任务:
- 文档排序:采用 Pairwise 对同一 Query 下多个候选 Doc 排序
- 任务微调
- 数据:人工/大模型标注数据
- 任务:
- 相关性分档:
- 分类任务:对标注档位进行分类预测
- 回归任务:将档位映射为浮点数,转为回归任务可以捕捉到类别之间的有序性,同时可以缓解不平衡问题
- 相关性分档:
3.5.2、模型蒸馏
BERT 由于其较高的推理耗时,直接部署线上通常会采用知识蒸馏的方式将训练好的大模型知识迁移到小模型中,这种方法通常要比直接训练小模型效果要好。在相关性算法阶段,通常用精排单塔模型蒸馏粗排相关性双塔模型,48层大模型给6层小模型蒸馏。
3.5.2.1、蒸馏算法
蒸馏算法通过最小化学生模型的输出与教师模型的输出之间的差距来训练学生模型。通常,采用两种损失函数:
-
硬标签损失(Hard Label Loss)
- 硬标签损失是基于真实标签(ground truth)计算的损失,通常使用交叉熵损失。硬标签损失 $\mathcal{L}_{\text{hard}}$ 为:
- 其中:
- $y_i$ 是第 $i$ 类的真实标签(通常是 one-hot 编码)
- $\hat{y}_{s,i}$ 是学生模型预测的第 $i$ 类的概率
-
软标签损失(Soft Label Loss)
- 软标签损失通过教师模型的输出(即软标签)来计算,这些软标签是教师模型在推理过程中产生的概率分布(softmax 输出)。软标签损失 $ \mathcal{L}_{\text{soft}}$ 通常使用 KL 散度(Kullback-Leibler Divergence) 来度量学生模型的输出与教师模型的输出分布之间的差异。具体的公式为:
- 其中:
- $ \hat{y}_{t,i}$ 是教师模型对第 $i$ 类的预测概率
- $\hat{y}_{s,i}$ 是学生模型对第 $i$ 类的预测概率
-
总损失函数
- 最终损失函数是硬标签损失和软标签损失的加权和:
- 其中:
- $ \alpha $ 和 $ \beta $ 是超参数,用于控制硬标签损失和软标签损失的权重
- $ \mathcal{L}_{\text{hard}} $ 是基于真实标签的交叉熵损失
- $ \mathcal{L}_{\text{soft}} $ 是基于教师模型输出的软标签损失(KL 散度)
-
温度调节(Temperature Scaling)
- 为了让学生模型更好地学习教师模型的输出分布,通常对教师模型的 softmax 输出进行温度调节。引入温度参数 $T$ 后,softmax 函数变为:
- 其中:
- $z_{t,i}$ 是教师模型的原始 logits 输出(即模型的未归一化预测)
- $T$ 是温度参数,通常 $T > 1$,增加温度后,softmax 输出的概率分布变得更加平滑
- $\hat{y}_{t,i}$ 是教师模型经过温度调节后的输出概率
3.5.3、样本构建
在训练数据的正负样本构建上,需要结合搜索交互行为和语义属性特征,尽可能的提升训练数据的质量:
- 正样本:
- 点击特征筛选:选取充足曝光下高 CTR 样本,筛选 Query 下文档点击率高于平均值的样本
- 语义属性筛选:根据 Query/Doc 类目/主题动态调整阈值
- 负样本:
- Skip-Above采样:仅选取在点击文档之前且CTR小于阈值的充分曝光的文档作为负例
- 随机负采样:同Batch中其他样本做负样本(去除类目一致或文本高度匹配的噪声样本)
- 数据增强:替换 Query 中核心Term构造负样本
- 跨类目采样:在同一父类目的不同叶子类目中进行负样本
3.5.4、LLM-as-a-Judge
在传统的任务微调中,高度依赖人工标注的 0-4 档相关性数据。然而,人工标注成本极高且存在主观偏差。目前业界普遍采用大语言模型作为裁判进行数据蒸馏与伪标签生成。
将相关的分档标准作为 System Prompt 注入 LLM,让 LLM 对 Query-Doc 对进行打分,并强制要求输出 CoT(思维链)解释原因。LLM 生成的不仅仅是绝对档位,还可以通过多次采样获取概率分布,转化为 Soft Label。将海量 LLM 标注的 Query-Doc 数据喂给线上的 BERT 单塔/双塔模型进行微调。
3.6、损失函数
3.6.1、Pointwise Loss
3.6.1.1、交叉熵(Cross Entropy,CE)
当相关性分档采用分类任务时,通常采用交叉熵损失,交叉熵主要用于衡量两个概率分布之间的差异:
\[\mathrm{CE}(y,{\hat{y}})=-\sum_{i=1}^{C}y_{i}\cdot\log({\hat{y}}_{i})\]- $y_{i}$ 是真实标签的独热编码向量,第 $i$ 类的标签为 1,其它类别为 0
- $\hat{y}_{i}$ 是模型对于第 $i$ 类的预测概率
3.6.1.2、均方误差(Mean Squared Error,MSE)
当相关性分档采用回归任务时,通常采用 MSE 损失,MSE 通过计算预测值与真实值之间的差异来衡量模型的性能:
\[\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2\]- $ n $ 是样本的总数量
- $ y_i $ 是第 $i$ 个样本的真实值(目标值)
- $ \hat{y}_i $ 是第 $i$ 个样本的预测值
- $ (y_i - \hat{y}_i) $ 是第 $i$ 个样本的误差
3.6.2、Pairwise Loss
3.6.2.1、对比损失
对比损失衡量两个文档的相对排序是否正确。如果文档对的相关性排序是正确的,那么损失应该较小;如果排序不正确,则损失应该较大:
\[\mathcal{L}_{\text{contrastive}} = \frac{1}{2} \left[ y \cdot d^2 + (1 - y) \cdot \max(0, m - d)^2 \right]\]- $ y $ 是文档对的标签,取值为 0 或 1,表示文档 $ D_1$ 是否应该排在文档 $ D_2$ 之前
- $ d $ 是文档 $ D_1$ 和 $ D_2$ 在模型预测中的距离(通常是两者的评分差)
- $ m $ 是一个超参数,表示 “margin”(边际),即在没有损失的情况下,文档的评分差需要达到的最小值
3.6.2.2、RankNet损失
RankNet使用 对数损失 来训练排序模型。RankNet 通过概率的形式预测文档的相对排序,给定一对文档 $ D_1$ 和 $ D_2$ ,模型输出一个概率,表示 $ D_1$ 比 $ D_2$ 相关的概率:
\[\mathcal{L}_{\text{RankNet}} = - \sum_{i,j} \left[ p_{ij} \log \hat{p}_{ij} + (1 - p_{ij}) \log (1 - \hat{p}_{ij}) \right]\]- $ p_{ij}$ 是文档对 $ D_1$ 和 $ D_2$ 的真实排序标签(如果 $ D_1$ 应该排在 $ D_2$ 前面,则 $ p_{ij} = 1$ ,否则为 0)
- $ \hat{p}_{ij}$ 是模型预测 $ D_1$ 排在 $ D_2$ 前面的概率
3.7、相关性评估
相关性常用指标有:
-
AUC
- 对于每个档位,计算该类别与其他类别的区分能力。即当前档位将作为正类,其余类别作为负类。AUC 值越接近 1,表示搜索相关性算法的排序性能越好,即越能将相关的文档排在前面,不相关的文档排在后面
-
DCG
- 通过计算排序结果中相关文档的累积增益(Cumulative Gain,CG),并根据文档的位置对其增益进行折扣,以便评估排序的质量
- 其中:
- $\text{DCG}_p$ 表示在前 $p$ 个文档的DCG值
- $rel(i)$ 表示排名第 $i$ 的文档的相关性评分
- $i$ 是文档的排名(从1开始,越前面的文档排名越高)
- $\log_2(i + 1)$ 是折扣因子,用来模拟文档排名越靠后的文档,用户查看它的概率越低,因此越低的排名对应着较低的增益
-
PNR
- 在一个排序列表中,计算正序对的数量与逆序对的数量之比。正序对是指在排序中,相关性更高的文档排在相关性较低的文档前面的对数,逆序对则相反。PNR 值越大,说明整个排序列表中正序的比例越多,即搜索结果的排序越合理
4、大模型时代的相关性
在传统的 BERT 模型中,相关性计算被视为一个判别式任务,通过线性层输出分类概率或回归分数。而在当前的工业界前沿,相关性排序正在向生成式任务演进。
4.1、生成式相关性排序范式
生成式排序放弃了传统的分类头,直接利用 LLM 的自回归生成能力来输出相关性结果。主要分为两种范式:
- Pointwise 提示排序: 将 Query 和 Doc 拼接,让 LLM 直接生成相关性分数或判断
- 输入:
Query: {query}, Doc: {doc}. Please output a relevance score from 0 to 4. - 输出:
3
- 输入:
- Listwise 列表排序: 利用 LLM 强大的上下文窗口,直接将多个 Doc 一起输入,让模型输出排序后的文档序列
- 输入:
Query: {query}, Docs: [Doc1, Doc2, Doc3]. Rank them by relevance. - 输出:
[Doc2, Doc1, Doc3]
- 输入:
虽然生成式范式在理解复杂语义上具有降维打击的优势,但直接使用交叉熵(CE Loss)微调 LLM 用于排序时,会面临严重的 “曝光偏差(Exposure Bias)”,且 CE Loss 优化的 Token 生成概率与真实的排序指标(如 NDCG)存在严重脱节。
4.2、强化学习优化生成式排序
为了解决生成模型目标与排序评价指标错位的问题,可以利用强化学习直接优化生成式排序相关性。将相关性排序建模为马尔可夫决策过程(MDP),并使用 PPO 算法,通过奖励机制直接优化 NDCG 等列表级指标。
4.2.1、MDP 建模
在生成式排序中,每输出一个相关性判定或文档位置,就是一个时间步(Step)。
- 状态(State, $s_t$):包含用户的 Query、待排序的文档列表 Docs,以及 LLM 已经生成的历史 Token 序列
- 动作(Action, $a_t$):LLM 的词表分布,即下一步要生成的 Token(例如生成具体的分数或文档 ID)
- 策略(Policy, $\pi_\theta(a_t \mid s_t)$):生成式大语言模型本身
- 奖励(Reward, $R$):通过外部的奖励模型(Reward Model),基于人工对齐的相关性标准打分,将生成列表的 NDCG 或 ERR 等排序评估指标作为连续奖励反馈给大模型
4.2.2、PPO 优化
为了使得 LLM 生成的相关性结果能够最大化长期回报(即最终的搜索列表质量),可以采用 PPO 算法进行策略更新。
1. 优势函数估计 (Advantage Estimation)
首先,使用一个 Critic 网络来预估当前状态的价值 $V(s_t)$,并计算优势函数 $\hat{A}_t$,它代表采取当前动作比平均情况好多少:
\[\hat{A}_t = R_t + \gamma V(s_{t+1}) - V(s_t)\]2. 策略更新截断目标 (Clipped Surrogate Objective)
为了防止模型在强化学习更新时策略变化过大导致崩溃,PPO 引入了重要性采样比率 $r_t(\theta)$:
\[r_t(\theta) = \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{old}}(a_t | s_t)}\]随后,对其应用截断函数(Clipping),构造损失函数 $\mathcal{L}^{CLIP}$:
\[\mathcal{L}^{CLIP}(\theta) = \hat{\mathbb{E}}_t \left[ \min \left( r_t(\theta)\hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t \right) \right]\]其中 $\epsilon$ 是截断超参数(通常设为 0.2)。通过最大化该目标函数,大模型在生成相关性判断时,会不断向能获得更高 NDCG 奖励的方向演化。
4.3、生成式相关性排序前沿落地
4.3.1、基于特定 Token Logit 的 Pointwise 算分
早期的尝试是让大模型直接输出“分数数字”,但这种自由生成的方式极其不稳定,分数不可比。目前的工业界标配是将相关性计算转化为特定 Token 的概率生成任务。
模型结构与 Prompt 设计上采用 Decoder-only 模型。输入固定格式的 Prompt:
输入:Given a query A and a passage B, determine whether the passage contains an answer to the query by providing a prediction of either 'Yes' or 'No'. \n Query: {query} \n Passage: {doc} \n Prediction:
在线上推理时,并不需要模型真的 “生成” 一段文本,而是在最后一个位置(<eos> 之前),直接提取词表中 Yes 和 No 两个 Token 的模型内部未归一化对数(Logits)。相关性分数 $S_{rel}(q, d)$ 通过对这两个特定 Token 的 Logits 进行 Softmax 计算得出:
在微调(SFT)阶段,采用标准的交叉熵损失函数。正样本的 Target 为 Yes,负样本(通过挖掘的难负例,Hard Negatives)的 Target 为 No。这种方案将大模型庞大的世界知识压缩到了一个精准的概率维度上,极大提升了相关性计算的稳定性和可控性。
4.3.2、Listwise 列表级重排与滑动窗口截断
Pointwise 算分忽略了文档之间的相对质量差异。为了让模型拥有全局比较的视野,业界演进出了 Listwise(列表级)排序。
大模型直接接收 Query 和一组候选文档,要求其直接输出按相关性从高到低排列的文档标识符序列。
输入:Query: {query}. Rank the following passages based on their relevance. \n [1] {doc_1} \n [2] {doc_2} \n ... [K] {doc_K} \n Output the ordered list of identifiers:
输出:[3] > [1] > [K] > ...
由于大模型存在 Context Window 长度限制,且长文本下会出现 “迷失在中间(Lost in the middle)” 的注意力衰减现象,很难一次性把粗排输出的文档全塞进去。工业界采用类似冒泡排序的滑动窗口策略。假设窗口大小 $W=20$,步长 $S=10$。系统从初始召回列表的最底端开始,每次取 20 篇文档喂给 LLM 进行局部 Listwise 重排,排好后窗口向上滑动 10 个位置继续重排。这种机制确保了最高相关性的文档能够像气泡一样,稳步且精确地浮到 Top-1 的位置。
4.3.3、Pairwise 排序提示与锦标赛排序
虽然 Listwise 看全局,但研究发现 LLM 在长 Prompt 中存在严重的 “位置偏见(Position Bias)” —— 倾向于给排在 Prompt 最前面或最后面的文档打高分。为了消除偏见,Pairwise Ranking Prompting (PRP) 成为了一种高精度的妥协方案。
Prompt 极其简单聚焦:Query: {query}. Document A: {doc_A}. Document B: {doc_B}. Which document is more relevant? Answer A or B.。
如果候选集有 $N$ 篇文档,两两比较需要进行 $O(N^2)$ 次 LLM 推理。工业界将大模型的 Pairwise 判断作为一个比较算子(Compare Function),直接套用经典的计算机科学排序算法,如堆排序(Heap Sort)或锦标赛排序(Tournament Sort)。比如,构建一个淘汰赛树状图,两两文档输入 LLM 进行 PK,胜者晋级。这样只需进行 $O(N \log N)$ 甚至更少次(如果我们只需要 Top-K)的大模型调用,就能获得具有严密逻辑支撑的高相关性排序列表。
4.3.4、基于大模型 CoT 的白盒知识蒸馏
在千万级 QPS 的通用搜索引擎中,让一个几十/上百亿参数的大模型在线上为每一条 Query 进行实时相关性打分,其计算延迟和算力成本依然是不可接受的。目前业内相关性团队最落地的做法是:将大模型作为线下相关性裁判机进行知识蒸馏。
针对海量复杂/长尾 Query,利用大模型进行打分,并强制要求输出思维链。线上的实时相关性打分依然使用轻量级的 BERT Cross-Encoder。但在训练时,不仅用 MSE 拟合大模型给出的 Soft Label 分数,还可以引入对比学习,让小模型的隐藏层向量去对齐大模型在输出 CoT 时的高维语义表征。
5、总结
搜索相关性衡量搜索引擎返回的结果与用户查询意图的匹配程度,是评判搜索系统质量的一个关键因素。相关性通常和搜索效率指标冲突(如点击率、转化率等),如一些为了吸引用户点击但相关性不强的文档会对用户产生误导诱发点击,当相关性模块将类似文档过滤就有可能带来搜索点击率的下降。
所以相关性必须有精确标准的一套相关性分档体系,帮助搜索系统在各种维度上优化排序结果。即,相关性策略的目标需要平衡相关性和搜索效率,清楚自己的功能定位,约束搜索排序以避免过度追求点击率而忽视了用户满意度,从长远上提高搜索系统的整体质量和用户体验。
