1、协同过滤召回
协同过滤 (Collaborative Filtering, CF) 是一种常用的推荐算法,主要基于用户的历史行为数据来预测用户对物品的偏好,从而实现个性化推荐。
在搜索领域,用户的搜索点击行为天然构成了一张庞大的 Query-Doc 二部图。协同过滤可以基于分析用户的行为数据(如点击、浏览、收藏、购买等)和文档之间的关联,为用户提供相关的召回结果。在 Query 改写 中已经介绍了如何用基于协同过滤的方法找到相似 Query,在本章节中会介绍基于协同过滤的相似文档 Doc 召回。
1.1、I2I 召回
I2I 召回 (item-to-item recall) 基于文档相似性的召回策略,即通过分析文档之间的关联性(如共同出现、相似特征等),从一个或多个初始文档出发,召回与其相关的文档集合。
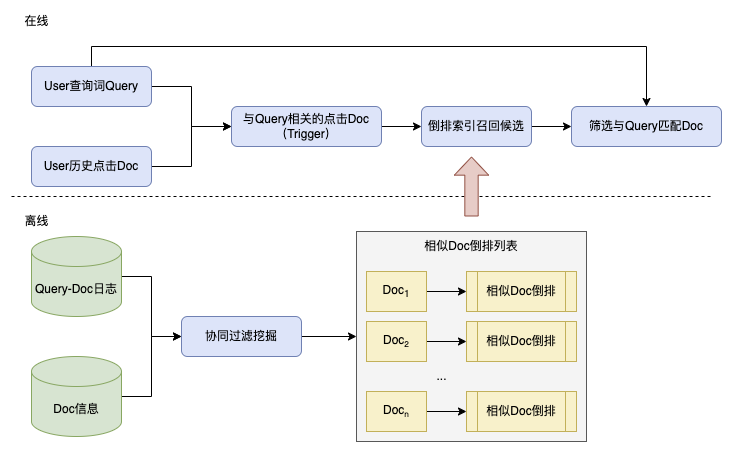
一种常见的 I2I 召回策略是基于推荐算法中的 U2I2I 召回,即基于用户的点击历史生成一个与当前用户搜索相关的 item list(doc list),将这些 item 作为 trigger,并利用 I2I (item to item) 相似度矩阵进行召回。具体如图:
-
线上流程
- 收集当前用户历史点击文档集合
- 从点击文档中筛选出和当前查询词 Query 相关的文档作为
trigger - 对
trigger文档通过倒排索引/KV 词表召回对应相似文档作为召回候选 - 从候选文档中筛选与查询词 Query 匹配的文档完成召回
-
离线流程
- 基于点击等行为构建 Query-Doc 点击二部图(这块也可以采用 User-Doc,Session-Doc 等构建图)
- 基于二部图通过协同过滤算法计算 Doc-Doc 之间的相似度
- 对于检索池中的每篇 Doc,按照相似度从高到低排序,取 TopN 构建倒排索引
1.1.1、基于向量表征的 I2I 召回
在 I2I 召回架构中,除了采用协同过滤的方法得到相似文档,基于向量表征的相似文档召回同样可以适配于 I2I 召回架构中。
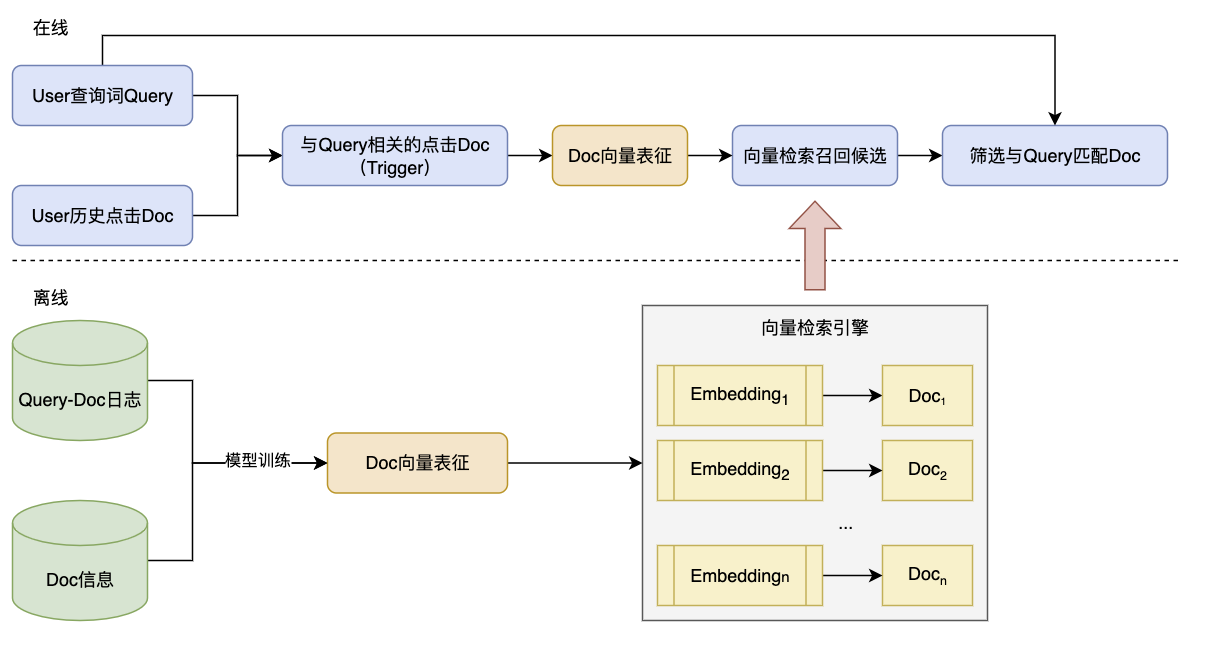
-
线上流程
- 收集当前用户历史点击文档集合
- 从点击文档中筛选出和当前查询词 Query 相关的文档作为
trigger - 将
trigger文本文档通过向量表征模型转化为向量表示 - 对
trigger向量通过向量检索召回对应相似文档作为召回候选 - 从候选文档中筛选与查询词 Query 匹配的文档完成召回
-
离线流程
- 基于点击等行为训练文档向量表征模型
- 对检索池中的每篇文档生成向量并作为向量检索引擎的索引
需要注意的是,对多个 trigger 向量同时做向量检索可能会带来召回引擎的性能压力。在资源算力不支持的条件下,可以将多个向量 Pooling 成单一向量以完成向量检索。同样的,索引侧也可做对应适配,即相似文档的 Embedding 聚合成单一向量,并作为索引映射多篇相似文档。
1.2、协同过滤算法
关于 ItemCf、Swing、SimRank++ 在 Query 改写中的应用已在 Query 分析的 Query 改写 中介绍,可以结合两种不同方向的应用来理解 ItemCF 和 Swing 算法。
1.2.1、ItemCF
基于 Query-Doc 点击二部图 的 ItemCF 算法 将搜索系统中的查询(Query)与物品(Doc)视为二部图的两类节点,通过用户的点击行为建立连接,并利用 ItemCF(基于物品的协同过滤) 方法挖掘文档之间的相似性。
通过 ItemCF 的相似度度量(如余弦相似度或共现频率)来计算每篇 Doc 的相似 Doc,具体的,如果两篇 Doc 与多个相同的检索 Query 关联,说明它们具有相似性,如下是采用余弦相似度的 ItemCF 计算公式:
\[\mathrm{sim}(d_{i},d_{j})=\frac{\sum_{q\in Q_{ij}}f(q,d_{i})\cdot f(q,d_{j})}{\sqrt{\sum_{q\in Q_{i}}f(q,d_{i})^{2}}\cdot\sqrt{\sum_{q\in Q_{j}}f(q,d_{j})^{2}}}\]其中,
- $Q_{ij}$ 是 Doc $d_{i}$ 和 Doc $d_{j}$ 共同点击关联的 Doc 集合
- $Q_{i}$ 和 $Q_{j}$ 分别是 Doc $d_{i}$ 和 Doc $d_{j}$ 各自点击关联的 Query 集合
- $f(q,d)$ 是 Query $q$ 和 Doc $d$ 的点击频率,通常用威尔逊平滑对点击次数和点击率进行平滑处理作为最后的点击频率(同样适用于 Swing):
其中,
- $\hat{p} = \frac{\text{clicks}}{\text{impressions}}$ 表示点击率(CTR)
- $n = \text{impressions}$ 表示曝光次数
- $z$ 是对应置信水平的 z 值,例如 95% 的置信水平对应的 $z \approx 1.96$
基于 ItemCF 可以建立 Doc-Doc 的索引,根据相似度打分对每个 Doc 选取 TopN 相似 Doc 作为召回候选。
1.2.2、Swing
Swing 算法以高维的网络结构向二跳节点扩展,具有强抗噪能力,与 ItemCF 不同, Swing 可以更加灵活地处理数据稀疏的情况。基于 Swing 算法的相似 Doc 挖掘建立在:如果两个 Doc 间关联的共点 Query 越多,且这些 Query 之间的重合度越低,那么这两个 Doc 间的相似度越高。如,Query u 和 Query v 点击了 Doc i,则三者构成 Swing 结构,若 Query u 和 Query v 不仅点击了 Doc i,Doc j 也被 Query u 和 Query v 点击,那么认为 Doc i 和 Doc j 在某种程度上是相似的,计算公式如下:
其中,
- $Q_{i}$ 表示点击 Doc $d_{i}$ 的 Query 集合,$Q_{j}$ 表示点击 Doc $d_{j}$ 的 Query 集合
- $I_{u}$ 表示 Query u 点击的 Doc 集合,$I_{v}$ 表示 Query v 点击的 Doc 集合
- $|I_{u}\cap I_{v}|$ 表示 Query u 和 Query v 的重合度,重合度高则要降低它们的权重,以避免意图不明确的 Query 带来噪声
上述 Swing 公式本质上在计算被 Doc $d_{i}$ 和 Doc $d_{j}$ 被点击关联的所有 Query Pair 的 Swing 结构(Query-Doc-Query)的权重之和。基于 Swing 可以建立 Doc-Doc 的索引,根据相似度打分对每个 Doc 选取 TopN 相似 Doc 作为召回候选。
1.3、图神经网络 (GNN) 与实时序列召回
在工业级搜索系统中,用户的行为不仅构成了一张错综复杂的网络(Query-Doc 图),更是一条随时间快速演进的意图流。图神经网络(GNN)和实时序列召回打破了传统协同过滤的局部性和滞后性。
1.3.1、图神经网络召回
传统的 Swing 或 ItemCF 只能利用 Query 和 Doc 的共现关系,本质上是二阶游走。而图神经网络(GNN)的核心优势在于多跳信息传递,它能够顺着 “Query $\rightarrow$ Doc $\rightarrow$ Query $\rightarrow$ Doc” 的拓扑结构,将高阶的相似性传播给冷门和长尾节点,缓解数据稀疏问题。
在工业界,目前落地最广泛、效率最高的 GNN 变体是 LightGCN。LightGCN 抛弃了传统 GCN 中繁重的特征变换和非线性激活函数,极其轻量且专为协同过滤设计。
LightGCN 的核心操作是线性邻居聚合,设在 Query-Doc 二部图中,令 $e_u^{(k)}$ 表示节点 $u$(可以是 Query 或 Doc)在第 $k$ 层的 Embedding:
\[e_u^{(k+1)} = \sum_{i \in \mathcal{N}_u} \frac{1}{\sqrt{|\mathcal{N}_u||\mathcal{N}_i|}} e_i^{(k)}\]- $\mathcal{N}_u$ 和 $\mathcal{N}_i$ 分别是节点 $u$ 和邻居节点 $i$ 的度(Degree,即连接边数)
- \(\frac{1}{\sqrt{\mid \mathcal{N}_u \mid \mid \mathcal{N}_i \mid}}\) 是对称归一化系数,用于防止超级节点(如爆款 Doc)导致 Embedding 爆炸
- 通过不断迭代 $K$ 层(工业界通常设 $K=2$ 或 $3$),节点不仅吸收了直接邻居的信息,还吸收了 $K$ 阶邻居的信息
最终,节点的表征是所有层级 Embedding 的加权和:
\[e_u = \sum_{k=0}^K \alpha_k e_u^{(k)}\]通常 $\alpha_k = 1/(K+1)$。
模型训练数据构造如下:
- 正样本:搜索日志中真实的 Query-Doc 点击边 $(u, i)$
- 负样本:对于给定的 Query $u$,从全局随机采样未点击过的 Doc $j$ 作为负例
损失函数通常采用 BPR Loss(Bayesian Personalized Ranking),这是一种 Pairwise 的排序损失,目标是让正样本的内积得分严格大于负样本:
\[\mathcal{L}_{BPR} = -\sum_{(u,i,j) \in \mathcal{D}} \ln \sigma(e_u^T e_i - e_u^T e_j)\]其中 $\sigma$ 为 Sigmoid 函数。
由于 GNN 训练需要整个图的全局拓扑结构,工业界通常采用离线图计算平台(如 GraphScope、Euler)进行分布式训练。训练完成后,导出所有 Doc 的最终高阶 Embedding 向量。将这些向量灌入 Faiss 或 Milvus 等向量检索引擎(ANN)。线上检索时,利用 Query 的 Embedding 或 Trigger Doc 的 Embedding 去 ANN 中进行极速的最近邻查询,完成高阶 I2I 召回。
1.3.2、实时序列召回
在电商和内容平台,用户的搜索意图是高度动态的。用户可能在一分钟内搜了 “帐篷”,接着搜了 “防潮垫”,此时他最急迫的隐式意图是 “露营装备”。传统的静态召回无法捕捉这种短期的时序意图转移。
实时序列召回通过建模用户在当前 Session 内的实时点击流,预测下一个最可能点击的 Doc。
工业界目前的主流方案是基于 Transformer 架构的序列模型,如 SASRec (Self-Attentive Sequential Recommendation) 或 BST (Behavior Sequence Transformer)。
模型将用户历史点击的 Doc 序列 $S = [d_1, d_2, …, d_t]$ 映射为 Embedding 序列,并加上位置编码。随后通过多头自注意力机制捕捉序列内部的依赖关系:
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]其中 $Q, K, V$ 均由历史行为序列的 Embedding 线性映射而来。通过自注意力机制,模型能够自动识别出历史点击中哪些 Doc 对预测当前的意图最重要,从而动态生成一个代表用户 “当前实时意图” 的稠密向量 $h_t$。
训练数据来源于用户的连续点击日志,假设一个用户的完整点击序列为 $[d_1, d_2, d_3, d_4]$,将序列拆解为多个监督样本:
- 输入 $[d_1]$,预测 $d_2$
- 输入 $[d_1, d_2]$,预测 $d_3$
- 输入 $[d_1, d_2, d_3]$,预测 $d_4$
这种 Next-Item Prediction 任务同样采用 Sampled Softmax 或 InfoNCE Loss 进行训练。
当用户发生点击时,客户端立即上报日志到 Kafka。Flink 实时消费日志,在百毫秒内将该点击 Doc 追加到该用户在 Redis 中的历史行为队列(Session Sequence)中。
当用户发起下一次 Query 时,搜索引擎不仅读取 Query 文本,还同时拉取 Redis 中刚刚更新的实时行为队列。将队列送入部署在 TIS/TensorRT 上的 Transformer 模型进行实时前向传播,生成用户当前的意图向量 $h_{user}$。
基于意图向量 $h_{user}$,去底层的向量检索引擎中拉取 Top-K 相似的 Doc,完成召回。整个链路在几十毫秒内完成。
1.4、总结
协同过滤算法在搜索召回中的应用,能够有效利用用户行为数据建模文档之间的关系。其中最基础的应用是采用 I2I 的召回框架,而在引入向量表征之后,可以升级为向量检索召回相似文档。即文档之间的相似性不再依赖共现数据,而是通过向量间的距离计算,实现了从简单线性关系到复杂非线性关系的提升。在实际业务中,可以根据业务需求、资源条件和模型能力选择适合的算法策略。
参考文献
- Amazon.com Recommendations Item-to-Item Collaborative Filtering
- Large Scale Product Graph Construction for Recommendation in E-commerce
