1、意图识别
Query 意图识别用于帮助理解用户在提交查询时的真正需求或目标,即将用户模糊或不完整的查询映射为系统能够理解的需求类型。意图识别通常依赖和服务于搜索相关产品,如:交易查询意图(如购买商品、预订服务等)、本地查询意图(如搜索附近的餐馆、电影院等)。本章将介绍常见的四种意图:
- 时效性意图
- 定义:用户的查询与当前时间或特定的时间范围密切相关,强调数据的实时性
- 产品策略:在结果中优先展示最新内容
- 本地化意图
- 定义:用户希望获取与特定地理位置相关的信息或服务,侧重地理位置的关联性
- 产品策略:在结果中优先展示距离最近的选项或提供地图视图
- 用户意图
- 定义:用户的查询直接涉及特定用户名、账号或社交媒体身份,关注个体身份或社交信息
- 产品策略:在结果中展示相关用户信息内容
- 交易意图
- 定义:用户的查询带有明确的购买或消费目的,通常包含特定的商品品类、品牌、型号或细粒度的修饰属性(如颜色、款式、尺码等)
- 产品策略:在结果中优先展示精准匹配其结构化属性的商品卡片(SKU),并提供价格、销量、品牌等维度的导购筛选选项
2、时效性意图
时效性意图强调数据的 “新鲜度(Freshness)”。用户不仅仅是在找相关内容,更是要求内容必须反映客观世界的最新状态。
时效性意图通常有以下两个特点:
- 查询中通常包含时间相关的词语,例如 “今天”、“最新”、“最近” 等
- 涉及动态更新的信息,如新闻、事件、天气、股价、体育比分等
根据 Query的时效性场景可以划分为三大类:
- 强时效性(突发热点 / 周期事件)
- 定义
- 突发事件:突发的新闻事件(重大事故、灾害、政治突发事件等)
- 热门话题:短期内被广泛讨论的事件或话题(热门社交话题、体育赛事、娱乐事件等)
- 语义时效性:周期性更新的信息,或者是希望获取最新版本的内容(天气预报、股价、节假日活动等)
- 搜索结果策略:保证头部曝光结果中新 Doc 的占比。除了暴力拉升新发 Doc 的排序权重,强时效性极易引来营销号 “蹭热点”。因此必须配套 “权威媒体/账号提权” 以及 “相似低质内容强折叠” 机制,确保头部首屏的纯净度与权威性。
- 定义
- 一般时效性(泛资讯)
- 定义:查询与时间相关,但对实时性要求不高,允许在一定时间范围内满足需求
- 搜索结果策略:提升搜索结果中新 Doc 的权重,在精排阶段引入时间衰减因子,在相关性与新鲜度之间寻找平滑的折中点。
- 无时效性
- 定义:查询与时间无关,不关注特定时间范围的信息
- 搜索结果策略:推荐权威或高质量的结果,结果中适当控制旧 Doc 的占比
2.1、时效性基础信号
通过建设时效性基础信号,识别查询 Query 和 Doc 的时效性,有效提升时效性意图搜索结果。对于突发热点事件需要建设热点事件识别流程以帮助判断 Query 是否指向热点事件。此外,对 Query 时效性区分通常借助语言模型和搜索后验进行识别判断。
2.1.1、热点事件识别
对于突发热点事件需要建立热点数据反馈机制,并据此判断检索词 Query 是否与热点内容相关:
- 通过站内站外两个渠道来源搜集和挖掘热点数据
- 将热点数据写入索引,构建实时更新的召回通道,并根据热点内容的时效衰减变化动态维护索引
- 在线将 Query 和召回的热点内容进行相关性匹配计算,截断后综合热点发布时间排序
- 根据排序后首条结果是否满足准出条件(与 Query 的相关性),判定 Query 是否为热点事件
2.1.2、Query 时效性识别
Query 时效性识别通常依赖基于语言模型的语义时效性打分以及搜索后验数据综合判断。
2.1.2.1、语义时效性打分
语义时效性分数采用 BERT 模型对 Query 进行打分,模型输入为 Query,输出为时效性分数。
在训练样本的构建上,除了人工标注数据,可以引入自动样本进行扩量:
- 基于点击时新 Doc 的挖掘: 挖掘给定时间周期内,点击高时效性 Doc 占比超过 $x\%$ 的 Query 作为正样本,反之作为负样本
- 基于共点 Doc 的挖掘: 基于已标注的强置信的 Query,通过 Query-Doc 点击二部图扩充该类别的 Query
2.1.2.2、Query 时效性分类
Query 时效性分类模型的输入为语义时效性打分和搜索行为统计特征:
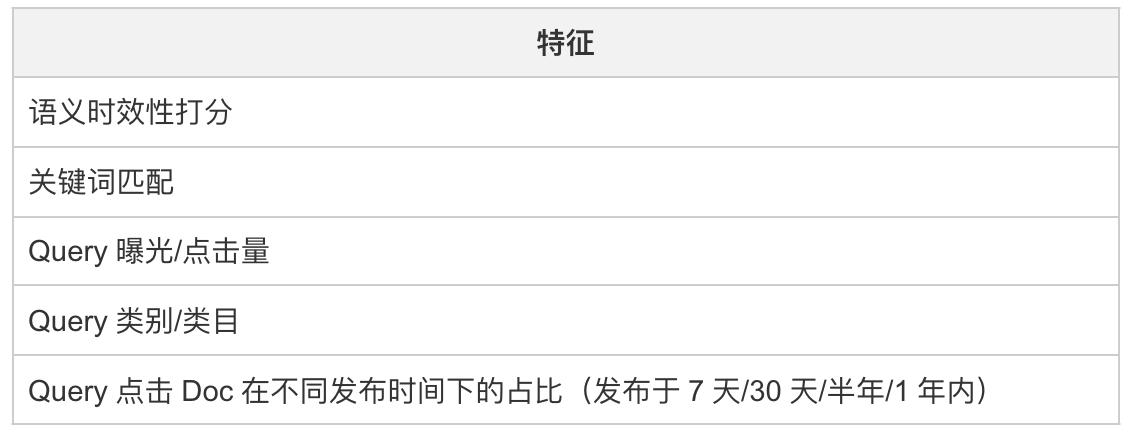
2.2、时效性信号应用
对于识别为强时效性的 Query,需要在搜索结果中优先展示新 Doc,同时需要保证头部曝光结果中的新 Doc 占比。具体的,可以对满足时效性要求的 Doc 在保证召回(如:增加时效性 Doc 召回通路)的同时,在排序阶段对新 Doc 的权重进行提升。对于突发热点数据可以进一步通过干预的方式保证结果在结果首位展示。
3、本地化意图
本地化意图(LBS, Location-Based Service)是指用户希望获取与特定地理坐标相关的实体或服务信息。在美团、高德乃至 TikTok 的同城 Feed 流中,这是最核心的变现意图。如:
- 查询附近的服务或设施(如“附近的咖啡馆”)
- 查询特定地点的活动或条件(如“北京明天天气”)
- 查找以地理位置为上下文的资讯或内容(如“上海有哪些好玩的地方”)
3.1、本地意图类别
用户可能明确或隐式表达位置需求:
- 显式位置意图
- 用户明确在 Query 中指出地理位置,通常包括地名、地址或地标
- 示例:
- “上海的五星级酒店”
- “纽约时报广场附近的餐馆”
- “东京迪士尼攻略”
- 隐式位置意图
- 用户未在 Query 中明确提及位置,但通过词语(如“附近”、“周围”)或上下文推断出位置相关性
- 示例:
- “附近的加油站”
- “周边好吃的火锅店”
- “离我最近的地铁站”
3.2、本地意图目标
本地意图需要识别出有位置需求的 Query,并对 Query 位置解析,将其与地理位置信息进行关联,如用户的实时 GPS 坐标、IP 归属地、当前时间段,从而实现对特定位置的信息检索。
- 意图分类
- 定义:本地化意图可以进一步细分为精搜、泛搜等维度
- 精搜意图: 用户明确地表达了具体的位置需求或服务目标,希望直接找到精确的答案或匹配的结果。需要重点提取具体的地理位置或服务类别,结合品牌关键词进行高精度匹配
- 泛搜意图: 用户需求较为模糊,通常是为了探索某个区域或服务类别的信息,没有明确的具体目标。强调范围和多样化扩展,结合位置上下文和用户偏好优化结果
- 示例:
- 精搜意图:上海新天地
- 泛搜意图:上海美食
- 位置解析
- 定义:从 Query 中提取地理实体(城市、 POI 等),推断位置范围需求(指定区域范围限定)
- 示例:Query = “北京故宫附近美食”,抽取得到城市 = “北京”, POI = “故宫”
- 多义性处理
- 定义:一些地名可能存在歧义,需要结合用户实时地理位置和上下文解析
- 示例:Query = “人民公园地铁站”,有很多城市有人民公园,需要结合具体的用户位置信息进行解析
- 多意图处理
- 定义:在查询中可能同时隐含多个位置或需求层次,导致搜索系统无法直接确定用户的目标位置或意图方向
- 示例:在上海搜 “北京烤鸭”
- 改场景包含两种位置需求
- 基于目标地点的内容需求(北京的烤鸭介绍或餐馆)
- 基于当前地点的服务需求(上海提供北京烤鸭的餐馆)
- 结合位置和上下文推测用户意图
- 如果用户近期多次搜索 “北京旅游攻略”,其意图更可能是查询北京本地信息
- 如果用户最近搜索了“附近的餐厅”,则可能是希望找到上海的北京烤鸭店
- 若查询发生在用餐时间,系统可倾向推测用户寻找上海的餐馆
- 改场景包含两种位置需求
3.3、本地意图模型
由于本地意图目标不仅需要实现意图识别,还需要完成位置解析,在模型可以选择基于 BERT 的意图识别和槽位填充模型的联合模型。
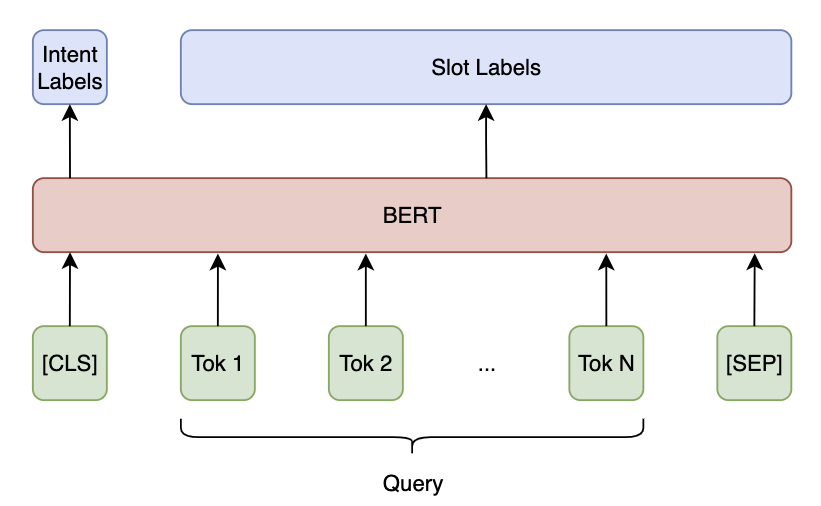
意图识别和槽位填充本质上分别为一个句子分类任务和一个序列标注任务,结合两者的 loss 即可实现多任务学习。给定 Query 文本,插入一个特殊的分类嵌入([CLS])作为第一个标记,并添加一个特殊的标记([SEP])作为最后一个标记。则输入序列为 $x=(x_{1},…,x_{T})$, BERT 输出序列为 $H=(h_{1},…,h_{T})$:
- 意图分类
- 基于第一个特殊标记([CLS])的隐藏状态 $h_{1}$,学习目标函数为: \(y^{i}=\mathrm{softmax}(\mathrm{W}^{i}h_{1}+b^{i})\)
- 槽位填充
- 基于隐藏状态 $h_{1},…,h_{T}$,学习目标函数为: \(y_{n}^{s}=\mathrm{softmax}(\mathrm{W}^{s}h_{n}+b^{s})\,,\,n\in1\ldots N\)
- 联合建模
- 目标函数为: \(p(y^{i},y^{s}|x)=p(y^{i}|x)\prod_{n=1}^{N}p(y_{n}^{s}|x)\)
- 学习目标是最大化条件概率: \(p(y^{i},y^{s}|x)\)
- 意图识别和槽位填充损失函数都采用交叉熵损失函数
提取出地点后,在底层召回引擎中,通常会采用动态距离约束:如果解析出意图是 “便利店”,搜索半径可能锁定在 1 公里内;如果是 “三甲医院” 或 “滑雪场”,搜索半径会膨胀到 50 公里。
4、用户意图
在一些有社交属性或 UGC 平台中,用户通常有涉及用户名称、用户账号的检索需求,检索内容一般为用户名、ID、昵称、标签等。这类需求往往旨在查找特定用户的信息、动态、或与之相关的内容,以满足社交互动、内容消费、或平台探索的目的。
用户意图的产品形态是基于用户查询行为和需求设计的功能模块或交互界面,通过解析用户意图并提供相关服务,提升用户体验和检索效率。
除了单独给用户检索的搜索界面外,一般在主界面的综合通搜页面内,对于有明确用户意图的检索词也会触发如小窗口之类的交互界面以展示意图相关的用户信息。
4.1、用户意图识别链路
用户意图模块的目标是识别有用户意图的 Query 并返回对应用户信息,常规的链路设计如下:
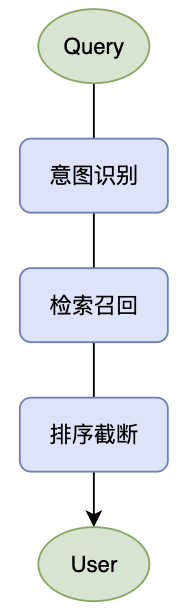
4.1.1、用户意图识别
由于用户意图 Query 在通用场景下流量占比通常较低,为了尽可能降低算力的消耗,在链路上一般会经由意图识别模块将有用户意图的 Query 筛选出来。而由于用户名、用户 ID 的文本构造通常有一定的规则,可以采用基于 TextCNN、 BERT 等语言模型做分类判断。
训练数据的正样本的挖掘上可采用以下方案:
- 百科人物数据
- 站内用户名称/昵称(满足高活跃度、高粉丝量等)
- 用户检索界面内历史高频检索词
- 综合检索主界面历史触发交互窗口的检索词
4.1.2、用户多路召回
对于触发用户意图识别的 Query 需要进一步通过召回检索模块实现相关用户的候选召回,召回算法可以是基于向量表征的向量召回、基于倒排的文本召回、基于词表的 KV 召回等。
为了尽可能的保证召回率,通常会根据索引的内容不同而涉及多路召回通道:
- 用户名召回通道
- 昵称召回
- 拼音召回
- 改写召回
- 向量召回
- 用户 ID 召回通道
- 标签/ 领域召回通道
- 关注列表召回通道
4.1.3、用户排序截断
对于召回的候选用户需要经过相关性判别和排序,去除低匹配相关用户和重名的低质用户(仿号、低活跃度用户等)。
4.1.3.1、相关性判别
采用 BERT 模型,输入为 Query 和候选用户信息(用户名/昵称/标签等信息),输出为相关性分数:
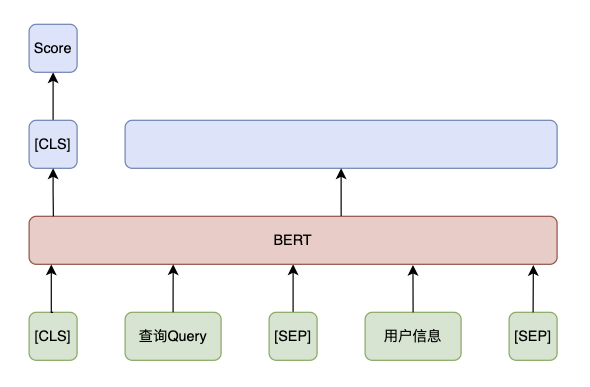
4.1.3.2、排序截断
对于满足相关性的候选用户,会通过结合后验行为特征的排序模型筛选出 TopN 作为最终检索结果展示。
排序模型常见特征如下:

5、交易与属性意图
对于电商、本地生活或垂类交易平台而言,识别用户的交易意图并精准抽取 Query 中的商品属性,是促成交易的前提。这类意图识别的本质,是将非结构化的自然语言 Query,转化为高度结构化的属性键值对,从而在底层倒排索引中执行精确的属性过滤。
5.1、交易意图的界定与分类
业界通常会先通过一个轻量级的分类模型(如 TextCNN 或轻量级 BERT)对 Query 进行宏观意图定性:
- 明确交易意图(精确寻址):如 “ iPhone 15 Pro Max 256G”、“耐克空军一号白”。用户目标极其明确,系统需要立刻启动严苛的属性抽取和精准匹配。
- 泛交易意图(逛街/导购):如 “送女友的生日礼物”、“冬季显瘦穿搭”。这类 Query 缺乏明确品类,系统会触发 “导购链路”,将意图转化为类目推荐或图文/视频种草内容召回。
- 非交易意图(问答/经验):如 “苹果手机怎么截屏”、“退货运费险怎么用”。系统会将其路由到客服 FAQ 或社区经验贴模块。
5.2、基于序列标注的属性抽取
一旦确认 Query 包含明确的交易意图,系统会进入属性抽取环节。在自然语言处理中,这是一个典型的命名实体识别(NER, Named Entity Recognition)任务。
电商搜索通常会定义数十种细粒度的实体标签,例如:[Brand: 品牌]、[Category: 品类]、[Color: 颜色]、[Material: 材质]、[Gender: 适用人群]、[Style: 风格/款式] 等。
主流模型演进:
- BiLSTM-CRF:
- 通过双向长短期记忆网络(BiLSTM)捕捉 Query 上下文特征,再通过条件随机场(CRF)约束输出标签的合法性(例如
I-Brand前面必须是B-Brand)
- 通过双向长短期记忆网络(BiLSTM)捕捉 Query 上下文特征,再通过条件随机场(CRF)约束输出标签的合法性(例如
- BERT-CRF:
- 利用预训练语言模型强大的上下文表征能力替代 BiLSTM。为了适应电商 Query 中存在大量行业黑话和缩写(如 “aj” 代表 Air Jordan,“神仙水” 代表 SK-II),通常会使用海量的电商标题和评价数据对 BERT 进行领域内的继续预训练
- FLAT:
- 由于电商领域词汇边界模糊,纯字粒度的模型容易切错(如把 “南极人” 切成 “南极/人”)。工业界目前常采用 FLAT(Flat-Lattice Transformer)等模型,在 Transformer 的注意力机制中显式注入电商名词词典的边界信息,实现字词特征的完美融合
5.3、级联工程架构
在线上高并发场景中,属性抽取架构通常采用 “词典规则 + 模型兜底 + 知识图谱校验” 的级联流水线:
- 第一层:AC自动机/字典树精准匹配
- 利用平台已有的海量结构化商品属性库,构建 Aho-Corasick 自动机。当输入“耐克男鞋”时,极速匹配出
[耐克: Brand]和[男鞋: Category]。这能解决 70% 常见且无歧义的头部 Query 需求,耗时仅需微秒级
- 利用平台已有的海量结构化商品属性库,构建 Aho-Corasick 自动机。当输入“耐克男鞋”时,极速匹配出
- **第二层:深度模型抽取 **
- 对于词典未覆盖的新词、长尾词或歧义词(如 “苹果”,需结合上下文判断是品牌还是水果),触发后端的 BERT-CRF 模型进行实时序列标注
- 第三层:常识与图谱校验
- 抽取结果必须符合客观商业逻辑。例如,如果模型将 “格力” 预测为
[Brand],将 “口红 ”预测为[Category],知识图谱会检测到 “格力” 与 “口红” 之间不存在生产关系(Edge),从而拒绝该抽取结果,防止召回系统产生 “零结果” 或严重语义漂移
- 抽取结果必须符合客观商业逻辑。例如,如果模型将 “格力” 预测为
5.4、训练数据构建
NER 模型通常需要数以百万计的 BIO 标注数据。人工标注成本高且无法跟上商品迭代速度。常见的做法是远程监督结合点击日志:
- 基于点击图谱的自动标注:
- 如果海量用户搜索了 Query = “2026新款aj1黑白”,并且最终大量点击、购买了某款商品。该商品的底层结构化属性是已知的(如
Brand: Air Jordan,Category: 篮球鞋,Color: 黑白)。 系统通过算法将商品的属性词反向 “映射/对齐” 到用户的 Query 文本上,自动生成训练语料:2026新款[aj1: Brand][黑白: Color]。
- 如果海量用户搜索了 Query = “2026新款aj1黑白”,并且最终大量点击、购买了某款商品。该商品的底层结构化属性是已知的(如
- 主动学习:
- 模型在训练过程中,系统会挑出模型预测置信度低的少量疑难 Case,送给人工进行打标。这能用最小的人工成本,最大化地提升模型对边界模糊词汇的泛化能力。
6、大模型时代的意图识别
随着大语言模型(LLM)的爆发,搜索架构的 QP 阶段正在经历一场深刻的范式转换。传统的意图识别高度依赖于 “人工定义类目树 + 海量人工标注数据 + BERT / CNN 判别式分类器”。这种模式在应对高频头部和腰部 Query 时效率极高,但在处理极度长尾、口语化、包含多重约束条件或逻辑推理的复杂 Query 时,常常面临泛化能力弱、槽位边界切分错误的瓶颈。
LLM 强大的 Zero-shot / Few-shot 理解能力、逻辑推理链(CoT)以及生成能力,正在重塑意图识别的工业界技术栈。
6.1、生成式结构化解析
在传统架构中,意图识别被局限在一个固定类别集合中,属性抽取则受限于 BIO 序列标注。一旦出现跨领域的复杂组合需求,传统模型直接宕机。
目前,业内开始将意图识别直接升级为 “信息抽取与逻辑重构” 任务。利用 LLM,将复杂的自然语言 Query 直接 “翻译” 为系统底层可执行的 JSON 结构或领域特定语言(DSL, Domain Specific Language)。
假设用户输入 Query:“帮我对比一下耐克和阿迪达斯的最新款碳板跑鞋,顺便看看上海徐家汇附近哪家有现货”。
传统模型极难同时处理对比意图、时效意图、商品意图和 LBS 意图。而 LLM 通过 Prompt 工程,可以直接输出如下高度结构化的意图解析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"query_type": "complex_mixed",
"sub_intents": [
{
"intent": "knowledge_compare",
"entities": ["耐克", "阿迪达斯"],
"attributes": ["最新款", "碳板跑鞋"]
},
{
"intent": "local_shopping",
"poi": "上海徐家汇",
"inventory_requirement": "in_stock"
}
]
}
底层检索引擎接收到这个 JSON 后,便可清晰地知道需要分别调用 “知识图谱问答库” 和 “同城库存商品库”。
6.2、知识蒸馏与数据合成
尽管 LLM 的零样本泛化能力极强,但在真实的工业搜索场景中,直接调用几百亿参数的大模型去做在线意图识别,其算力成本和数百毫秒的推理延迟是业务绝对无法接受的。
目前主流、成熟的 LLM 意图识别落地方案,是采用 “LLM as a Teacher” 架构:
- 线下海量数据合成:针对电商或内容搜索中极度缺乏训练样本的长尾/冷门意图(如某些小众专业器械的交易意图),通过设计 Few-shot Prompt,让 LLM 根据特定属性和意图标签反向生成用户 Query,极大地丰富了正样本池,解决传统训练样本高度不平衡的问题。
- 长尾 Query 自动打标:面对线上沉淀的千万级无标注长尾 Query,利用 LLM 作为 “最强标注员” 进行离线意图打分和槽位标注。
- 在线模型蒸馏:将 LLM 标注好的高质量结构化数据,喂给线上的轻量级小模型(如 DeBERTa、BiLSTM 甚至 FastText)进行有监督训练。
- 推理:上线后,线上推理仍然由极速的小模型(Student)承担,保持低延迟。
6.3、Agentic Search 路由分配
在企业级搜索和 AI 搜索助手中,大模型不仅是意图分类器,更是统筹全局的 Query Planner。
这种模式下,大模型作为一个中枢 Agent,它不再仅仅输出一个标签,而是对用户的复杂意图进行任务编排(Task Planning)和 API 路由(Routing)。
- 工作流:如针对 Query = “最近三个月马斯克收购了哪些公司,这些公司现在的股价如何”,LLM Agent 首先会判定该 Query 包含 “时效性/实体查询意图” 和 “金融意图”。
- 动态路由:Agent 会自动生成两步执行计划:
- 第一步,生成一条底层搜索指令去资讯库查询 “马斯克 近三个月 收购 公司名单”;
- 第二步,拿到返回的名单后,动态生成金融 API 请求,去调取实时的股价数据;最终将两部分结果融合成答案返回给用户。
7、总结
意图识别是用户检索体验中的核心环节,通过分析用户的查询内容和上下文,精准判断用户的真实需求,为后续的结果召回、排序和推荐提供有力支持。围绕不同场景,意图识别有多种维度和类型,其复杂性与丰富性决定了平台对用户需求的满足程度和交互质量。
随着大语言模型(LLM)的全面爆发,意图识别的边界正在被无限拓宽。从传统的判别式分类器,到生成式结构化解析,再到大模型驱动的 Agent 路由引擎,系统对用户意图的理解正在从 “词汇层面的猜测” 走向 “逻辑层面的共情”。
意图识别是检索技术与用户体验的结合点,其复杂性与灵活性决定了平台在多样化需求中的竞争力。无论是时效性、本地化还是用户名意图,理解用户真实需求并精准满足,有助于提升用户对平台的信任感和依赖度,增强用户粘性。总之,理解并满足用户需求始终是产品优化和技术创新的核心方向。
