1、Query 纠错
Query 纠错本质上是 Query 改写中的子集,其主要针对用户输入中的拼写、语法、或格式错误,自动将错误的查询改正为正确的形式。通常来说,在通用搜索领域中,错误的 Query 在流量维度的占比大致在 1%~2% 左右,一些垂类搜索由于查询涉及领域专业术语,错误 Query的流量占比可能会高达 10%。虽然错误 Query 的占比较少,但是其对搜索质量、用户体验有较大影响,反映在业务指标上主要体现在:Query 点击率、Query 换词率、Doc 零少结果率等。
Query 纠错的产品形态和应用方式主要有以下三种(业界通常简称为 Hard、DYM、Soft):
- 直接纠错 (Hard Correction / Auto-Correction)
- 当系统强置信判定 Query 错误时,直接对 Query 进行修正,搜索系统采用纠错后的 Query 进行检索,并给出可交互的提示词:“已为您显示
x的搜索结果,仍然搜索y”,其中x为纠错后的 Query,y为原检索词,用户仍可以点击原检索词y以显示y的搜索结果
- 当系统强置信判定 Query 错误时,直接对 Query 进行修正,搜索系统采用纠错后的 Query 进行检索,并给出可交互的提示词:“已为您显示
- 纠错建议 (Did You Mean / DYM)
- 系统提供可能的纠正建议供用户选择,用户可以直接接受建议进行搜索。与直接纠错不同,纠错建议让用户参与决策,允许用户决定是否采纳修正。系统此时仍然显示以原检索词 Query 进行检索后的结果,并给出可交互的提示词:”您要搜的是不是
x“,其中x为建议的纠错 Query,用户可以点击x获得以纠错 Queryx检索后的结果
- 系统提供可能的纠正建议供用户选择,用户可以直接接受建议进行搜索。与直接纠错不同,纠错建议让用户参与决策,允许用户决定是否采纳修正。系统此时仍然显示以原检索词 Query 进行检索后的结果,并给出可交互的提示词:”您要搜的是不是
- 纠错包含 (Soft Correction / Blending)
- 系统在底层隐式触发,展示的检索结果中不仅包含原检索 Query 的 Doc,同时也 “混排” 了纠错 Query 召回的优质 Doc
主流的纠错架构采用 pipeline 的方式:错误检测、候选召回、候选排序。由于纠错模块通常处于搜索链路最上游,QP 其他模块强依赖纠错结果,所以纠错模块需要尽可能的轻量化处理以保证时效性。另一方面,纠错由于其面对大量多样化的 Corner Case,为了保证纠错效果需要做技术精细化处理造成纠错系统复杂度较高,在实际线上应用中充满各种挑战,在设计上需要在效果与成本上要有多方权衡。

1.1、评测指标
衡量纠错系统的技术指标如下:
- FAR(误纠率): 正确 Query 被错纠的数量 / 正确 Query 总数
- Precision(精确率): 错误 Query 被正确纠正的数量 / 触发纠错的数量
- Recall(召回率): 错误 Query 被正确纠正的数量 / 错误 Query 总数
1.2、错误类型
常见的 Query 错误类型如下:
- 同音字错误: 弹枇杷 –> 弹琵琶
- 近音字错误: 砸汁机 –> 榨汁机
- 形近字错误: 麻辣哈利 –> 麻辣蛤蜊
- 词序颠倒: 工人智能 –> 人工智能
- 多字少字: 汽车油 –> 汽车油耗
- 汉字拼音混合: 考试报名fei –> 考试报名费
- 英文错误: chargpt –> chatgpt
1.3、错误检测
Query 纠错系统中一般需要检错模块用来判定当前 Query 是否错误,检错模块可以避免一些过纠、误纠的情况。另外由于线上真实错误 Query 的流量占比较低,而纠错系统的性能消耗通常较高,检错模块可以过滤掉大量无需纠错的搜索流量,避免给纠错系统带来性能压力。
常见的检错方式主要基于白名单知识库、历史搜索统计特征和语义信息。具体的,可以通过 Query 历史搜索统计特征(是否高频输入、高频点击、召回精确匹配 Doc 等)、百科数据知识库、用户反馈等信息构建白名单,命中白名单则判定无需纠错。为了保证纠错召回率,检错白名单只需保留强置信的无需纠错 Query 即可。
此外,还可以基于文本语义判断 Query 是否出错,业内常用的检错语言模型采用 BERT + Softmax 的方式对 Query 进行字粒度的序列化标注,即对每个字输出标签表示是否错误:
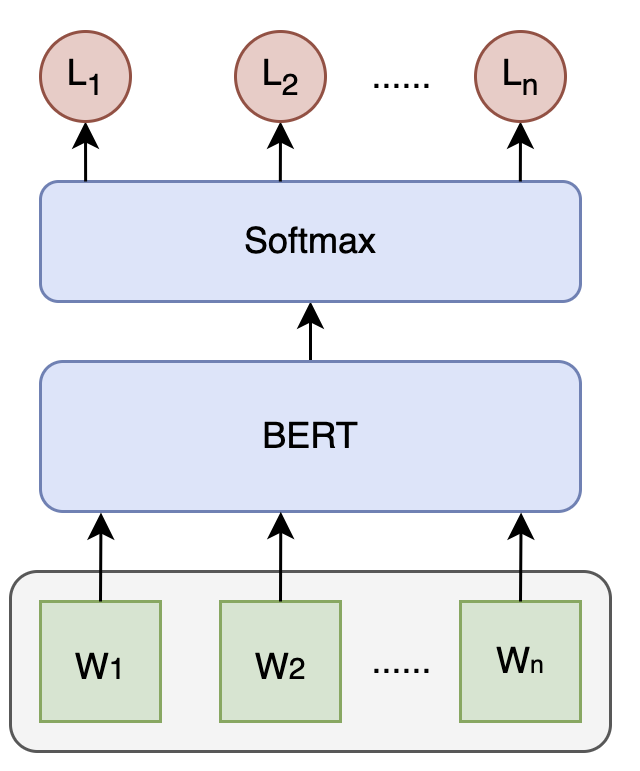
1.4、候选召回
为了尽可能覆盖各种纠错类型,通常需要设计多路纠错候选召回。常见的纠错候选召回包括基于词表的 BK 树 召回、基于混淆字词集的解码召回、基于字/拼音的倒排索引召回、基于 BART 的生成式召回。
1.4.1、BK 树召回
BK 树(Burkhard-Keller Tree)基于编辑距离(Levenshtein 距离,包括插入、删除、替换),是一种用于高效查找相似元素的树形数据结构。
BK 树的构建方式如下:
- 初始化根节点:
- 选择一个字符串作为根节点
- 插入新字符串:
- 对于每个待插入的字符串,计算其与当前节点字符串的编辑距离
- 如果当前节点没有相同编辑距离的子节点,则新建一个节点;如果存在,则递归地在该子节点处进行插入
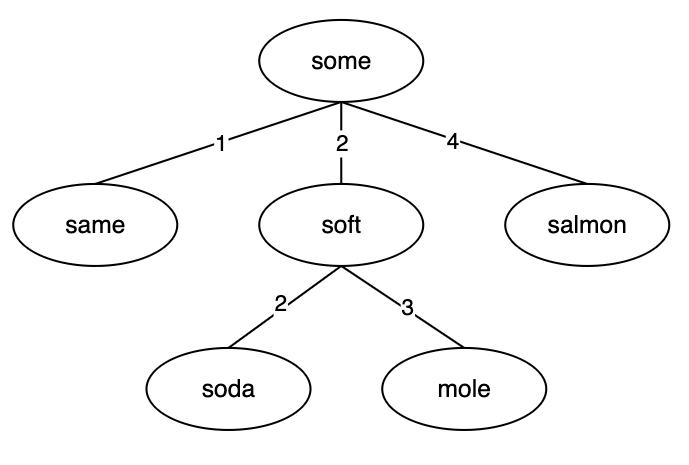
如上图:
- 以 some 作为 root 节点
- 插入 same,与 some 编辑距离为 1,建立新节点关联 some,边权重为 1
- 插入 soft,与 some 编辑距离为 2,建立新节点关联 some,边权重为 2
- 插入 soda,与 some 编辑距离为 2,递归插入到 soft 节点下,建立新节点关联 soft,边权重为 2
- 插入 mole,与 some 编辑距离为 2,递归插入到 soft 节点下,建立新节点关联 soft,边权重为 3
- 插入 salmon,与 some 编辑距离为 4,建立新节点关联 salmon,边权重为 4
BK 树查询方式如下:
- 计算查询字符串的编辑距离:
- 计算查询字符串与当前节点字符串的编辑距离
- 递归查找:
- 如果当前节点与查询字符串的编辑距离在指定的容忍范围内,则将该节点视为匹配项
- 递归搜索子树中与查询字符串编辑距离在允许范围内的所有节点。递归过程中,只有当子树的编辑距离与查询字符串的编辑距离相差在一定范围内时才会继续递归,否则跳过该分支
- 剪枝优化:
- 在搜索过程中,如果某个分支的编辑距离大于查询字符串与当前节点的编辑距离的容忍范围,则可以剪枝,跳过这个分支,从而提高查询效率
BK 树的词表构建方式和错误检错中的白名单类似。在通过 BK 树 获取纠错 Query 后,可基于统计特征变化(曝光/点击量)、Ngram 语言模型概率、字形拼音编辑距离、PMI 互信息变化等特征对候选结果过滤,并选取 TopN 作为 BK 树 召回 通道的结果。
1.4.2、SymSpell 召回
虽然 BK 树通过三角不等式减少了搜索空间,但其查询时间依然会随着词典规模的增大而增加。在工业界动辄上千万的纠错词典面前,BK 树的性能往往无法满足高并发要求。因此,目前大厂基于编辑距离的召回标配是 SymSpell (Symmetric Delete Spelling Correction) 算法。
SymSpell 的核心思想是 “空间换时间”,它仅仅使用删除操作来替代传统的插入、删除、替换操作,从而将查询的时间复杂度降到了 $O(1)$。
构建与查询流程:
- 离线预处理(构建 Hash 词典):
- 遍历词典中的每一个正确词汇
- 针对每个词,生成编辑距离在 $k$(如 $k=2$)以内的所有删除组合
- 将这些 “删除后的残缺词” 作为 Hash 表的 Key,将 “原始正确词” 作为 Value 存入。(例如:原词
apple,删除一个字符后生成pple, aple, appe, appl,它们均指向apple)
- 在线实时查询:
- 当用户输入错误 Query(如
aple)时 - 对输入的错误 Query 同样执行删除字符操作(生成
ple, ale, ape, apl等) - 将 Query 及其删除组合直接去 Hash 表中进行 $O(1)$ 的命中查询。如果它们之间存在交集,数学上即可证明原 Query 与正确词典词汇的编辑距离必定 $\le k$
- 当用户输入错误 Query(如
相比 BK 树,SymSpell 速度提升了成百上千倍,解决了拼音纠错和英文纠错中的性能障碍。
1.4.2、混淆集解码召回
解码召回通过混淆字集等对 Query 中的字词进行替换获得纠错候选,并通过基于 GBDT 的排序模型选择满足阈值的 TopN 结果作为混淆集解码召回通道的结果。
1.4.2.1、字词混淆集构建
与 Term 改写的 PT 表构建方法类似,字词混淆集以 Query-Title、共点 Doc 的 Query-Query、用户 Session 内的 Query-Query 等做为对齐语料,通过对齐规则/模型,在同音、近音、形近等约束下挖掘得到多粒度(字、词、短语)的混淆集,混淆集格式为三元组<原词,转移词,转移特征>。
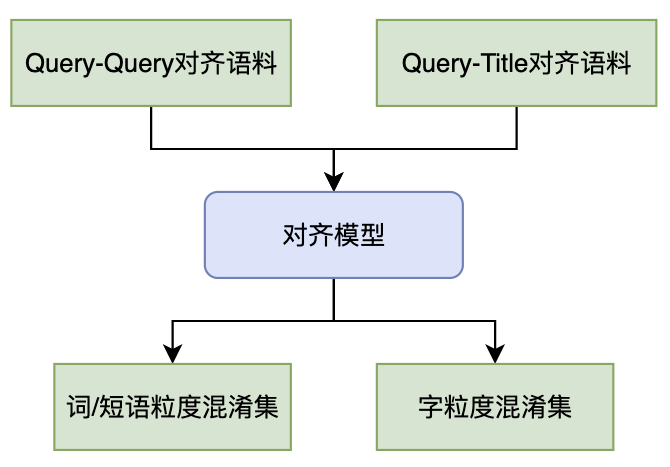
1.4.2.2、解码候选召回和排序
得到字粒度和词粒度的混淆集后,即可对 Query 纠错 位置进行字/词替换构建候选纠错:
- 对 Query 进行细粒度分词和字粒度切词
- 可基于 BERT 检错模型序列标注对纠错位置进行限制
- 对纠错位置的字/词从混淆集中召回候选,完成匹配替换
- 对候选结果聚合、去重、排序,选择满足阈值的 TopN 的结果作为混淆集解码召回通道的结果
混淆集解码召回通路的排序模型通常采用轻量级的 GBDT 模型,常见的特征如下:
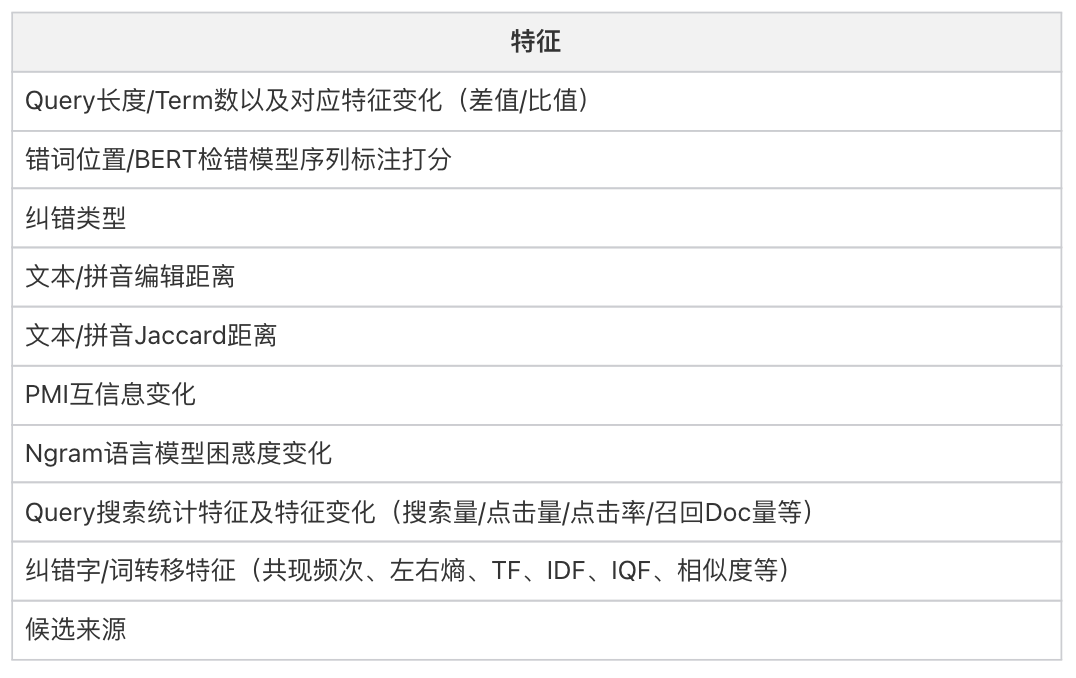
1.4.3、倒排索引召回
对白名单词表构建倒排索引:
- 创建候选词变体:在索引中保存所有词汇的变体以实现模糊匹配,变体的实现通过通配符符号实现
*:表示任意字符(或一组字符,根据编辑距离限制)。例如,appl*可以匹配apple、applle、appl等变体?:表示单个字符的变体。例如,a?ple可以匹配apple、ample等变体^:可以表示字符的顺序变动。例如,n^ot可以匹配not和ont
- 生成倒排索引:对于每个词汇的所有变体,都需要为其创建倒排索引
- 查询纠错:对查询词 Query 生成限定编辑距离内的变体,然后使用倒排索引召回相关文档,保留有效编辑距离较短的作为纠错候选召回
与 BK 树、混淆集召回相同,对倒排索引召回的纠错候选需经过后处理过滤筛选 TopN 纠错候选作为倒排索引召回通道结果。
1.4.4、BART 生成式召回
传统的 Pipeline 方式迭代成本高,纠错能力受各模块制约,在算力充沛和延时支持的情况下,采用类似于 BART 的生成式纠错召回是最佳方案。BART 的训练方法基于去噪自编码器(denoising autoencoder),这意味着它在处理损坏的文本和恢复缺失信息方面特别强大。对于 Query 文本纠错任务,BART 可以很自然地处理输入文本中的错误并生成正确的文本。
1.4.4.1、BART
BART 是一个结合了自编码器和自回归模型的预训练模型,其编码器能够处理文本的上下文信息,而解码器生成每个输出词时依赖前面生成的词。
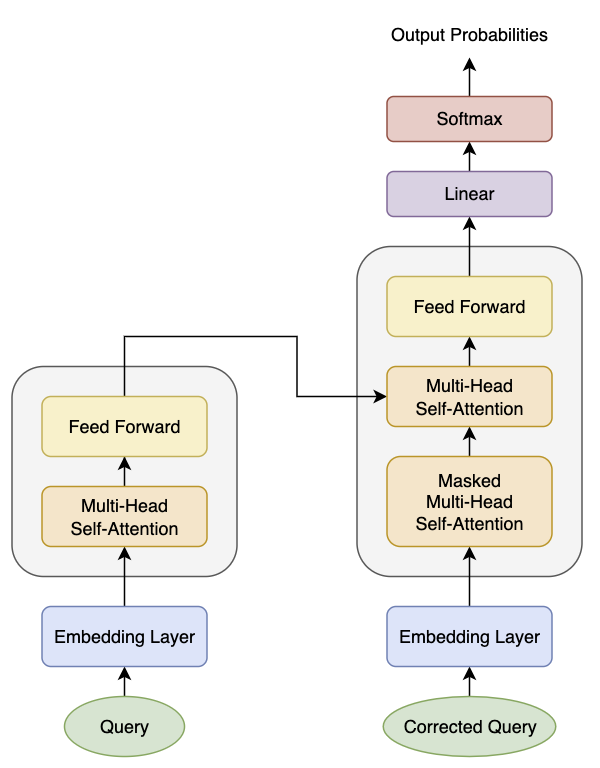
如图,左侧结构为 Encoder,右侧结构为 Decoder,Decoder 中的遮蔽注意力层关注 Decoder 过去所有的输入,而第二个注意力层则是使用 Encoder 对整个句子的输出。
1.4.4.2、训练集构建
BART 的训练数据以每一对(错误 Query,正确 Query)作为一条训练样本,错误 Query 为输入,正确 Query 为目标输出。
BART 的纠错微调训练需要大量的训练样本,除去人工标注和线上挖掘数据,还可通过规则替换和语言模型大批量生成数据:
- 基于规则生成错误 Query
- 对正确 Query 通过混淆集字词替换、字符交换、增删字符、模拟键盘误触等生成错误 Query
- 基于语言模型生成错误 Query
- 利用微调后的 T5、BART、GPT 等生成模型对正确 Query 生成错误 Query
对于构建的纠错数据,需要平衡正样本和负样本的比例,以及保证覆盖不同类型的纠错,同时确保训练数据与线上分布相近,避免生成的数据过于离谱。
BART 的 Decoder 需要逐字吐出结果,对于必须实时生成的长尾 Query,通常会将其蒸馏为一个极其轻量级的非自回归(NAR)模型,或者采用不对称层数设计(如 6 层 Encoder + 2 层 Decoder),配合 FasterTransformer 等算子级加速框架进行 Serving。
1.4.5、Google Search:基于 EdiT5 的局部编辑生成
Google 并没有采用传统的 BART 或 T5 强行端到端生成,而是从模型架构底层进行了改造,即 EdiT5(Edit-based Text-to-Text Transfer Transformer)。
在绝大多数搜索纠错中,Query 里 90% 的词是正确的,不需要修改。如果用传统的 Seq2Seq 模型把正确的词再重新生成一遍,是巨大的算力浪费。EdiT5 将生成任务拆解为了两个阶段:
- 阶段一:非自回归序列标注(Non-Autoregressive Tagging)
- 模型首先作为一个标注器,快速扫一遍输入的 Query,给每个 Token 打上 “编辑指令” 标签。标签包括:
KEEP(保留)、DELETE(删除)、REPLACE(替换)、INSERT(插入)。由于是打标签,这一步可以全并行计算,速度极快。
- 模型首先作为一个标注器,快速扫一遍输入的 Query,给每个 Token 打上 “编辑指令” 标签。标签包括:
- 阶段二:局部自回归生成(Targeted Autoregressive Generation)
- 进入 Decoder 阶段时,模型仅仅针对那些被标记为
REPLACE或INSERT的局部位置进行自回归生成。对于被标记为KEEP的部分,直接从输入端复制到输出端。
- 进入 Decoder 阶段时,模型仅仅针对那些被标记为
为了训练 EdiT5 的 Tagging 模块,Google 利用序列对齐算法(类似编辑距离溯源),将海量搜索日志中的 <错词, 对词> 转化为一条条带有 KEEP/DELETE/REPLACE 标签的训练样本,让模型学会像人类编辑一样去 “修改” 句子,而不是 “重写” 句子。
模型在训练时,不仅要输出最终的纠错词,还要预测出每一步的编辑操作,两者的 Loss 联合反向传播,提升对复杂长句的控制力,避免了传统生成式模型容易产生的 “幻觉”。
通过 EdiT5 的架构创新,解码器生成的 Token 数量通常从几十个锐减到了 1~2 个。配合 Google 底层 TPU 的定制化硬件加速、INT8 模型量化,以及对 KV Cache 的优化,Google 将这个拥有数亿参数的生成式纠错模型,在海量并发的真实搜索场景中,压缩到了单次推理 3 毫秒。
1.5、候选排序
经过 BK 树、混淆集、倒排索引召回和 BART 生成获得纠错候选后,为进一步保证结果的准确率,需要对候选聚合打分,判定最终的纠错结果和纠错应用类型。
在候选纠错排序中,通过 BERT 模型从文本语义理解角度对纠错候选打分。此外,仅从 Query 维度实现检错和纠正通常是不足的,缺失了 Query 关联 Doc 的信息应用,通过对原检索 Query 和纠错 Query 进行预检索获得 Doc 信息可以有效辅助纠错决策。
1.5.1、纠错预检索
实现纠错预检索实现流程:
- 构建一个轻量的索引库(通常采用倒排索引),索引库选择高质量的 Doc(高曝光点击、时效性高、非广告营销等)
- 原始查询和纠错候选分别使用 BM25 模型进行检索,获取相关文档
- 基于检索的相关性文档信息,作为特征辅助优化纠错
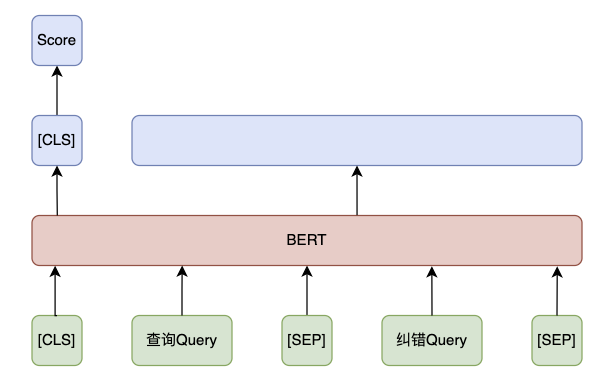
1.5.2、BERT 判别
BERT 纠错排序输入为查询 Query 和纠错 Query,输出纠错置信度分数。另外,在提高模型效果上,可以在训练样本中添加 side information,比如 Query 关联的 Doc 信息作为上下文 Context。
1.6、用户反馈采集和退场机制
纠错误纠会严重影响用户的搜索体验,用户反馈采集和退场机制是非常重要的组成部分。它们帮助系统不断改进和适应用户需求,确保系统能够动态调整和优化,提升用户体验和系统性能。
常见的反馈信息:
- 明确反馈:用户明确表示是否接受纠错建议。例如,在纠错提示下用户点击交互行为
- 隐性反馈:用户行为数据,如点击行为、查询行为、停留时间等,可以间接反映纠错的效果。例如,用户在收到纠错建议后是否继续点击相关结果,或者是否改变查询词
- 错误报告:用户主动报告错误或不满意的纠错建议,通常通过按钮、留言、投诉等方式提交
当收集到一定规模的反馈数据可以用来作为白名单词库以及模型训练数据集。对于可能造成舆情的紧急的突发纠错问题需要触发退场机制及时干预问题 Case,避免影响用户体验。
1.7、总结
Query 纠错面对拼写多样性、复杂性性和实时性等挑战,涉及的错误类型种类繁多,不同类型的错误往往需要采取不同的纠错策略和技术。另一方面,纠错的目标比较明确,高质量的模型训练数据集很大程度上决定了纠错效果的上限。随着技术的发展,基于生成模型的纠错算法已成为主流,但也面临着算力成本和实时性等挑战。在实际应用中,需要根据具体场景和需求选择合适的技术方案。
参考文献
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- EdiT5: Semi-Autoregressive Text Editing with T5 Warm-Start
