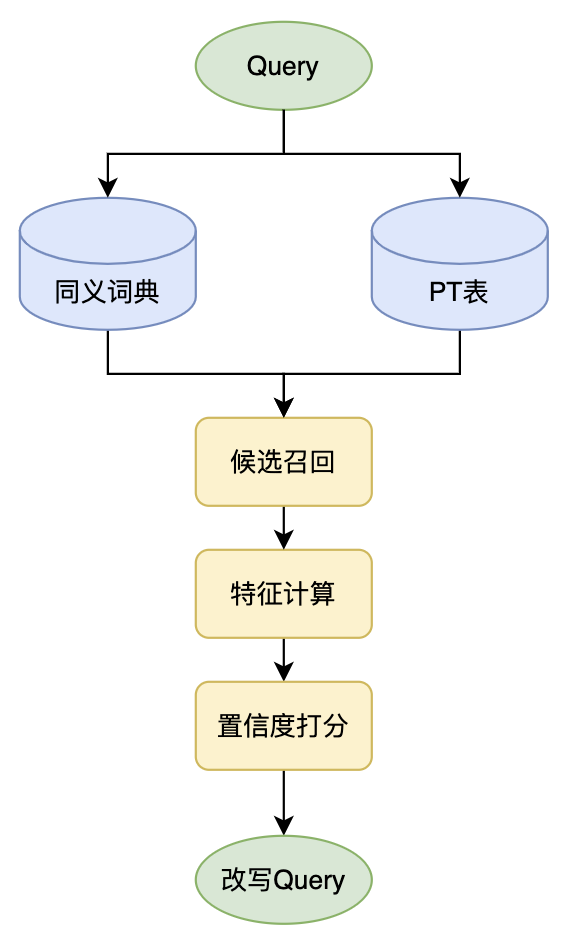
1、Term 改写
改写是 QP 中的重要组成部分,在搜索系统中,用户输入的查询词(Query)和文档之间可能存在用词不一致的情况,或者同一意思可以通过不同的表达方式传达。通过同义改写,检索系统可以更好地理解查询和文档的语义匹配,从而提高检索的相关性和结果召回量。
工业界常见的改写方式主要有两种,基于分词的 Term 粒度匹配改写和全词 Query 粒度改写。Term 粒度改写是指将 Query 分词为多个 Term 词序列,通过 Term 同义词替换实现语义泛化,如:宝宝辅食 –> [宝宝, 辅食] –> [婴幼儿, 辅食]。Query 粒度改写指直接对 Query 做语义泛化,如:瘦身饮食计划 –> 减肥食谱。
本章节将详细介绍 Term 改写,对其下游应用、技术方案两块进行展开。
1.1、布尔检索应用
Term 改写主要应用在搜索召回检索模块,如基于倒排索引的 Term 文本匹配召回通路。
假设有 Query 可以被分词为 [A, B, C],基于布尔检索的召回会根据分词构建查询串表达式:A and B and C,即检索结果 Doc 的文本内容需要同时包含Term词 A、B、C,若 A 有同义Term词 A1、A2、A3,B 有同义 Term 词 B1,则查询串表达式可以构建为:(A or A1 or A2) and (B or B1) and C。
当以结合同义词的布尔查询串进行检索时,由于原 Term 词和同义 Term 词是 OR 的关系,即检索命中同义词的笔记也会被召回,由此可以较大的提高相关结果召回量。此外,改写词可以作为特征参与相关性排序模块中。
更进一步的,直接进行平权的 OR 替换可能会导致严重的语义漂移(Drift):
-
权重惩罚:工业界通常会引入词权重衰减机制。对于改写词
A1,会根据其与原词A的相似度赋予一个折扣系数(如0.8)。底层的查询表达式实际上是(A^1.0 OR A1^0.8) AND ...。这样在相关性算分(如 BM25)时,命中原词的 Doc 得分会显著高于仅命中改写词的 Doc -
上下位控制:改写具备强烈的方向性。通常允许 “下位词向单向位词改写”(如 “iPhone 15” -> “苹果手机”),但严格限制 “上位词向下位词改写”,以防召回过度收敛或引发用户体验问题
1.2、数据挖掘
Term 改写的数据来源主要有两类:同义词典和 PT 表(Phrase Table),其中同义词典中的数据格式一般为有向二元组 <w1, w2>,表示 w2 是 w1 的同义词;而 PT 表存储的是两个词和两者的关联信息,并不显式表示两者是同义关系,格式为 <w1, w2, feat>,其中 feat 表示 w1 到 w2 的转移特征(对齐特征)。
1.2.1、同义词典
同义词典的语料一般来自于现有的辞海、百科、知识图谱等知识库数据,比如很容易可以从辞海中挖掘出:<中国, China>。此外也可以通过人工标注、模型判别对隐式匹配(向量召回)语料进行筛选和过滤后写入词典。大语言模型(LLM) 目前被广泛应用于同义词的批量生成。通过精心设计的 Prompt,LLM 能够从海量低频长尾 Query 中精准抽取出高质量的有向同义词对,经人工校验后打入线上词典。
1.2.2、PT 表
1.2.2.1、数据来源
PT 表的数据深度依赖于用户的海量历史搜索行为,主要通过构建点击二部图(Bipartite Graph)来提取平行句对:
- Query-Title:通过用户点击 Doc 的 Title 和搜索词 Query 构建平行句对
- Query-Doc-Query:若不同的 Query 在历史日志中高频点击了同一篇 Doc,那么这些 Query 之间天然构成了平行句对关系(协同过滤思想)
- Session:短时间内,同一用户多次修改 Query 进行检索,那么这些连续的 Query 之间构成平行句对
1.2.2.2、粒度对齐与图表示学习
根据数据源挖掘出海量的 Query-Doc 平行点击句对后,由于原始点击行为发生在 Query 粒度,而 PT 表的构建目标是 Term 粒度的改写,因此必须解决 “粒度不对齐” 的工程痛点。目前工业界主要采用以下三种技术手段,完成从 Query 级行为到 Term 级语义的跨越计算:
1. 两步走策略:Query 相似度挖掘 + 传统词对齐
这是最经典的基线方案。首先,在原始的 Query-Doc 点击二部图上运行 SimRank 等图算法,挖掘出高度相似的 Query 对。随后,将这些高频共现的 Query 对视作机器翻译中的平行语料,以共有词为锚点,反向推导并提取出局部的 1-gram 或 N-gram 词对齐关系。
对齐方式如下:
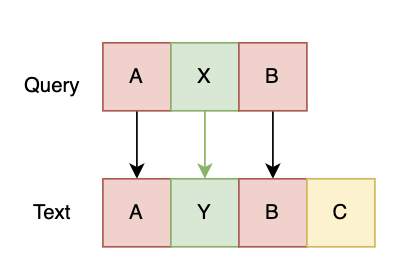
假设有 Query=AXB,Text=AYBC,以共现词 A 和 B 作为锚点,则 X 和 Y 构成 1-gram 词对齐,AX 和 AY 构成 2-gram 词对齐。另外可以采用文本翻译领域中的词对齐工具实现词对齐(如 FastAlign、GIZA++)。
2. 图重构:基于 Term-Doc 二部图的降维挖掘
为了省去复杂的对齐步骤,工程上常在建图阶段直接进行 “降维拆解”。系统打破 Query 边界,将 Query 分词后的 Term 直接作为节点与 Doc 建立边连接:
- 建图逻辑:若用户搜索 “苹果手机壳” 并点击了某数码 ,图中将直接生成
Term(苹果) -> Doc_1与Term(手机壳) -> Doc_1两条边 - 表示学习:在这个海量的 Term-Doc 二部图上运行 DeepWalk 等随机游走算法。若
Term(苹果)和Term(iPhone)频繁连接到相似的 Doc 节点群,算法便能直接赋予它们在拓扑结构上高度接近的 Embedding 向量表征,从而产出 Term 级别的图相似度
3. 异构图网络(Heterogeneous Graph):多粒度融合
在更前沿的表示学习架构中,通常会构建同时包含 Term、Query、Doc 三类节点的异构图网络:
- 关系定义:图中包含 “包含关系边”(如
Term(宝宝)Query(宝宝辅食))和 “点击关系边”(如Query(宝宝辅食)Doc(某商品))。 - 信息传递:通过 GraphSAGE 或 Node2Vec 的变体算法在图中进行随机游走,游走路径(如
Term(宝宝) -> Query(宝宝辅食) -> Doc(辅食商品) -> Query(婴儿辅食) -> Term(婴儿))巧妙地打破了粒度隔离。最终,将三类节点映射到同一高维连续的向量空间中,直接计算任意两个 Term 节点的余弦相似度(Cosine Similarity),即可精准召回语义及上下文高度一致的同义改写词
1.2.2.3、对齐特征
根据平行语料挖掘出大量词对齐数据后,即可统计出对齐特征,常见的特征如下:

有了词和对齐特征即可构建 PT 表作为线上 Term 改写的候选召回。
1.3、模型预测
当离线挖掘构建出 PT 表后,对于输入的查询词 Query 将通过 PT 表获取改写 Term 和相关特征后,则可通过树模型(GBDT)或轻量级 DNN 预测判别 Query 中的 Term 是否可以替换成召回的改写 Term,流程如下:
- 对查询词 Query 进行分词获得 Term 序列
- 对Term 序列构建 N-Gram 短语(1-3 gram)
- 对 N-Gram 短语通过 PT 表查询得到改写候选短语和对齐特征
- 对召回的 PT 短语进行对应 Term 替换,组成改写 Query
- 针对每个改写 Query 基于 Term 替换点构建特征
- 全局特征:Query / 改写 Query 语言模型得分,Query / 改写 Query 统计特征(检索量)等
- Term 词粒度特征:PT 表固有的对齐特征
- 上下文特征:替换点前后组成的 N-Gram 对齐特征
- 语义特征:原 Term 与改写 Term 的 Embedding 向量余弦相似度
- 通过 GBDT 或轻量级 DNN 模型 模型打分,判别当前 Term 改写是否可行(GBDT 模型可通过人工标注数据集训练得到,学习目标可以是样本关系,如同义 / 近义 / 无关)
1.4、总结
综上,Term 改写可以抽象为以下流程,并可分为离线数据挖掘和在线模型预测两个部分,一个好的改写系统可以有效降低长尾低频 Query 的零少结果率和 Query 换词率等指标。