1、词权重(Term Weighting)
词权重(Term Weighting)指搜索引擎在处理用户查询时,用于衡量用户查询(Query)中每个词(Term)的重要程度。这种重要程度的评估对于搜索引擎准确理解用户意图、召回相关结果并排序至关重要。词权重信息主要应用在以下场景:
- 丢词重召:在强匹配模式下召回结果较少或为空(Zero-Result)的情况下,系统会按照词权重从低到高的顺序逐步丢弃非核心词(如修饰词、停用词),对保留的核心词重新进行召回,以达到扩大召回面的目的
- 相关性排序与截断:在倒排索引求交时(如 WAND 算法,即倒排链动态截断),利用词权重对长倒排链进行动态截断,提升检索效率;同时,词权重是计算 Query 与 Doc 相关性分数的强特征,直接影响最终的相关性分档。除了作为特征,也可以在相关性模型训练时用作数据增强(如丢弃核心词以构建负样本)
- Query 改写指引:在进行同义词扩展或意图改写时,通常只对高权重的核心词进行扩展,或者在引入同义词时根据原词权重赋予同义词相应的衰减权重,防止语义漂移
词权重依赖前置的分词模块。即首先对 Query 分词获得 Term 序列,然后利用语料统计信息、点击日志等判断每个 Term 的重要程度。而如何确定词重要性决定了词权重的优化方向。本章节先介绍词权重的定义和标注规则,然后对词权重算法进行介绍。
1.1、词权重标注与定级
工业界通常将词权重划分为明确的 4 档(3-0档),并赋予不同的业务语义(通常被称为:必留词、核心词、修饰词、停用词):
- 3 档(必留词 / Mandatory):Query 的核心意图词。当该词被丢弃或替换时,Query 语义完全改变,检索出的 Doc 将被判定为严重不相关
- 2 档(核心词 / Core):Query 核心意图的重要组成部分。丢弃时语义有较大损失,但剩余词汇仍能检索到部分符合原意图的泛化 Doc
- 1 档(修饰词 / Modifier):通常在 Query 中起属性修饰作用。丢弃后 Query 的主干意图基本不变,且可以检索到绝大部分符合需求的泛化结果
- 0档(停用/冗余词 / Stopword):丢弃后 Query 意图完全不发生变化,且检索到的 Doc 基本都符合原意图。包含各种语气词、标点符号或无意义占位符
根据词权重的档位定义,我们可以得知,词权重信号判断依赖两个信号:先验的语义信息和后验的检索召回信息。在具体的词权重的标注过程中,可以结合具体搜索场景下的难/易 Case,根据语义和检索信息完成词权重标注任务。
1.2、词权重算法
在完成数十万量级的训练样本标注后,接下来的核心工作就是特征工程构造与模型打分。经历了从传统的纯统计方法(如 TF-IDF)到机器学习,再到深度学习的演进,目前业内通常采用特征驱动的监督模型与基于点击日志的弱监督模型相融合的方案。
1.2.1、特征挖掘
单纯依靠统计学(如经典的 IDF 即逆文档频率)无法完全解决语境多变的问题。一个完善的词权重预测模型通常会挖掘以下维度的特征:

1.2.2、模型打分
获取特征后,词权重任务通常被建模为分类任务(多分类 0-3 档)或回归任务(输出 [0,1] 连续分数)。模型输入为 Term 粒度下的 Term 特征,输出为 Term 的标签,模型可以根据情况选择树模型或 DNN 模型。
除了上述常规的数据标注 + 模型预测的方法,也可采用点击数据训练一个双塔模型,利用Query侧塔的注意力层中间结果作为词向量的权重(也可作为监督模型的特征采用),具体的:
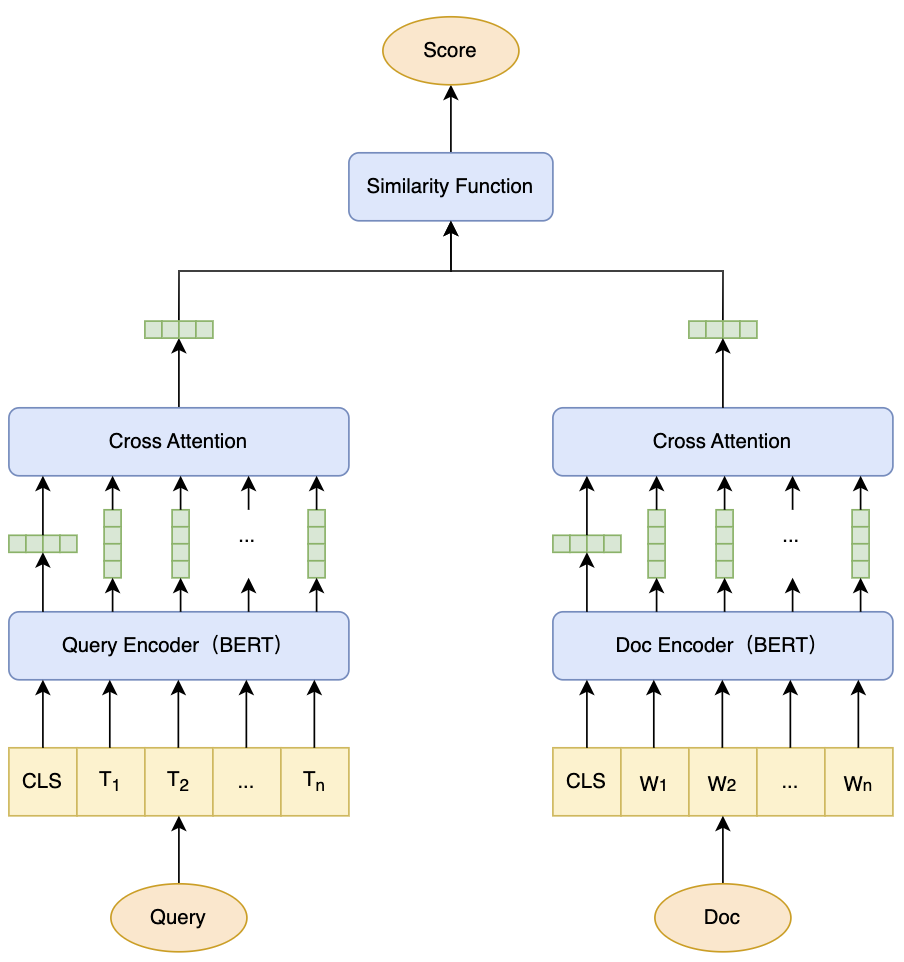
- 对 Query 和 Doc 分词,并分别输入到对应的 Encoder 模块(通常是小参数量的 BERT 或 Transformer)获取词向量表征、CLS向量表征(作为全局文本语义信息表征)
- 对于 Query 和 Doc 双塔,其对应 CLS 向量表征(Q)和词向量表征(K、V)经过交叉注意力层获得 Query 向量和 Doc 向量
- 使用相似度度量来计算这两个向量的匹配度,常用方法有点积或余弦相似度
- 最后经过激活函数(如 Sigmoid)将匹配度映射到 [0,1] 区间,模型的最终目标是预测用户是否点击该 Doc
- 模型完成训练后,Query 塔中注意力层的 attention score($ \mathrm{score}={\frac{\bf q\cdot k_{i}}{\sqrt{d_{k}}}} $)便天然反映了该 Term 在促成用户点击时的贡献度。这个分数可以直接被截取作为词权重,或作为强特征输入给下游的监督模型
近年来,基于预训练大模型的上下文感知词权重评估成为主流。模型不仅看词本身,更看词在这个特定 Query 句子中的作用。通常做法是将整个 Query 输入 BERT 等模型,直接在每个 Token 的输出表征上接一个全连接层,通过回归的方式直接拟合出该 Token 的权重分数,这使得词权重的预测具备了极强的动态上下文理解能力。
1.3、总结
综上,本章介绍了词权重在搜索系统里的应用,以及词权重分档定义和标注准则,另外在算法实现上介绍了常用的文本特征和统计特征,以及相关模型设计。
参考文献
- Term-weighting approaches in automatic text retrieval
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
